随着互联网的发展,搜索引擎爬虫(也称为搜索机器人或蜘蛛)的爬取行为成为了网站运营者关注的重要问题。它们会遍历你的网站,搜索并更新引擎的检索结果,以便他人可以找到你的网站。
如何巧妙运用robots.txt文件掌控蜘蛛的爬取行为,成了网站管理员的一项必备技能。
然而,值得注意的是,尽管robots.txt规则至关重要,但搜索引擎蜘蛛并不一定会严格遵守这些规定,因为它只是一个执行方针。
对于那些不受欢迎的恶意爬虫,你还需要研究如何通过.htaccess文件里的User-agent来阻止它们。
编辑和创建robots.txt文件是保护网站安全的一环,该文件必须放置在网站根目录下,以便被访问。
例如,如果你的网址是example.com,robots.txt文件可以在以下地址找到:
http://example.com/robots.txt
如果你的服务器位置是:
/home/userna5/public_html/robots.txt
若没有该文件,你可以使用纯文本文件创建一个新的robots.txt文件。
针对搜索引擎蜘蛛的User-agent,使用robots.txt文件来控制它们的访问行为是最常见的做法。搜索蜘蛛在爬取网站时,会以User-agent来进行识别。
以下是美国三大常见搜索引擎蜘蛛的User-agent:
Googlebot
Yahoo! Slurp
bingbot
而以下是被阻止访问最频繁的搜索引擎蜘蛛:
AhrefsBot
Baiduspider
Ezooms
MJ12bot
YandexBot
robots.txt文件包含许多规则,可以控制搜索蜘蛛如何爬取你的网站。User-agent可以具体指定哪一个User-agent适用,如*可以应用于所有的User-agent。
Disallow规定了哪些文件或目录不允许被搜索蜘蛛访问。
如果你的网站拥有大量页面,搜索蜘蛛可能在短时间内检索全部网站,导致服务器资源过度消耗,影响网页的访问速度。可以通过设置Crawl-delay来限制搜索蜘蛛的访问频率,从而分散服务器负载。
比如,延迟30秒将允许搜索蜘蛛在8.3小时内检索1000页网站。
允许搜索蜘蛛爬取全部网站的设定:
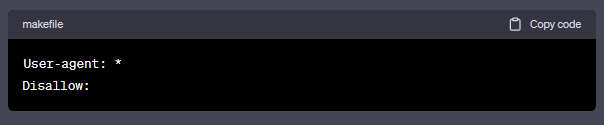
不允许搜索蜘蛛爬取全部网站的设定:

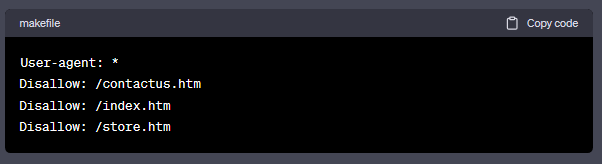
除了指定的以外,不允许搜索蜘蛛爬取的设定:
最后,如果你只希望Googlebot爬取你的/private/目录,而其他搜索蜘蛛不被允许,可以使用以下规则:
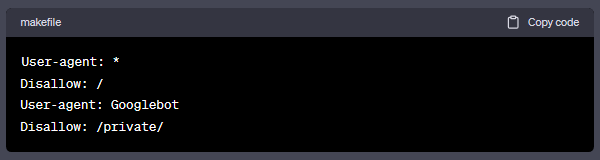
这样设置后,Googlebot在读取你的robots.txt文件时将会理解其中的内容,并不会被禁止访问其他目录。