背景
在开发中,为了低成本实现预渲染,本项目提供了一种非侵入性的解决方案:
无需改动业务代码,直接屏蔽框架差异
无依赖、简单易用,仅需拷贝粘贴脚本即可实现功能
开源代码,代码量仅一百多行,清晰易懂,方便二次集成
请注意,该项目主要适用于低成本的中小型项目。对于大型商业项目,建议参考下述成熟方案:
SSG 预渲染:使用 Prerender SPA Plugin,集成了 puppeteer,可自动运行项目、截取内容,生成页面元素
SSR 服务端渲染:使用 Next.js(React 应用程序的服务器渲染框架)或 Nuxt.js(Vue.js 应用程序的服务器渲染框架)
工具效果
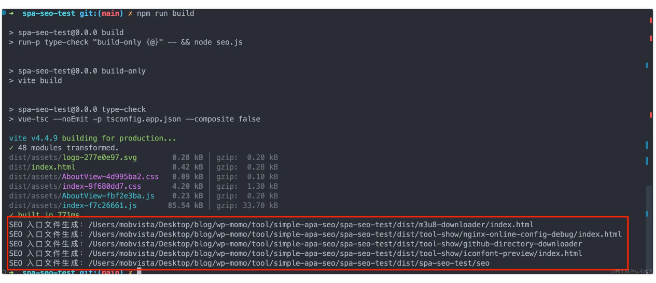
该工具能够在指定目录生成以 index.html 为模板的入口文件
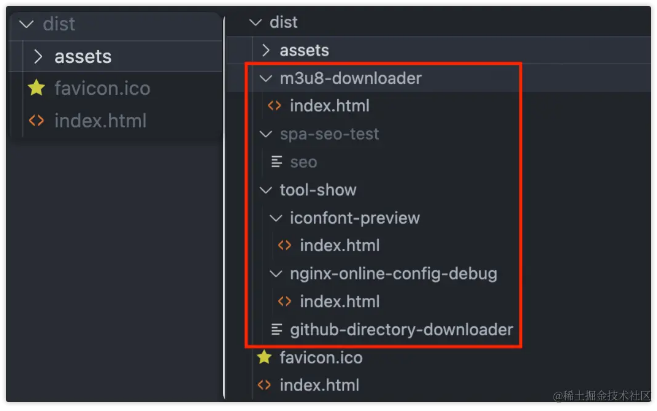
并在每个入口文件中实现自定义的 SEO 配置。用户可以轻松定制 title、keywords、description 等信息,从而提升单页应用的搜索引擎优化效果。
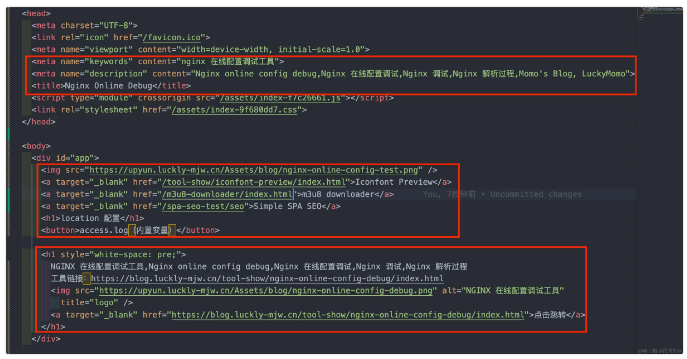
功能
pageLinkNum: 自动生成页面间的超链接跳转,实现页面间关联效果。将其设置为 0 则关闭该功能。
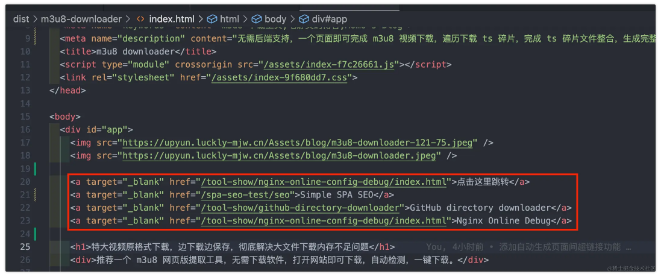
path: 需要对外暴露的路径,脚本将自动在相对路径生成对应入口文件。注意,无需刻意携带文件后缀,通过后文 Nginx 的一行配置,可将无后缀文件统一以 HTML 文件类型返回,让浏览器正常解析。

title: 指定页面的 title,如 <title>m3u8 downloader</title>。
keywords: 指定页面的 SEO 关键字,如 <meta name="keywords" content="m3u8 下载工具,毛静文的博客,Momo's Blog">。
description: 指定页面的 SEO 摘要,如 <meta name="description" content="无需后端支持,一个页面即可完成 m3u8 视频下载,遍历下载 ts 碎片,完成 ts 碎片文件整合,生成完整视频文件。">。
img: 设置页面的图片,实现搜索引擎收录,并在展示效果时展示缩略图。
link: 设置页面的超链接跳转,使搜索引擎的蜘蛛爬虫可以按照超链接找到系统中其他页面的链接,提供相关页面的入口。
content: 设置页面主体文案内容,使搜索引擎可匹配关键字。
html: 其他自定义标签,提供自定义插入特定 HTML 代码的功能。
{ path: '/m3u8-downloader/index.html', // 访问链接 title: 'm3u8 downloader', keywords: "m3u8 下载工具,毛静文的博客,Momo's Blog", description: '无需后端支持,一个页面即可完成 m3u8 视频下载,遍历下载 ts 碎片,完成 ts 碎片文件整合,生成完整视频文件。', // 页面描述 img: [ 'https://upyun.luckly-mjw.cn/Assets/blog/m3u8-downloader-121-75.jpeg', 'https://upyun.luckly-mjw.cn/Assets/blog/m3u8-downloader.jpeg' ], link: [{ text: '点击这里跳转', href: '/tool-show/nginx-online-config-debug/index.html', }], content: [{ tag: 'h1', text: '特大视频原格式下载,边下载边保存,彻底解决大文件下载内存不足问题', }, { tag: 'div', text: '推荐一个 m3u8 网页版提取工具,无需下载软件,打开网站即可下载,自动检测,一键下载。', }], html: ` 页面加载中,请耐心等待... <h1 style="white-space: pre;"> 推荐一个 m3u8 网页版提取工具,无需下载软件,打开网站即可下载,自动检测,一键下载。 工具链接:https://blog.luckly-mjw.cn/tool-show/m3u8-downloader/index.html 工具教程:https://segmentfault.com/a/1190000021847172?_ea=32289224 <img src="https://upyun.luckly-mjw.cn/Assets/blog/m3u8-downloader-121-75.jpeg" alt="m3u8 视频下载工具" title="logo"/> <a target="_blank" href="https://blog.luckly-mjw.cn/tool-show/m3u8-downloader/index.html">点击跳转</a> </h1> `, }
用法
拷贝项目的 seo.js 文件,并修改配置项。
在命令行中执行脚本,使用 node seo.js 运行。

若要集成到 package.json 的 script 中,可以在 package.json 文件中添加:
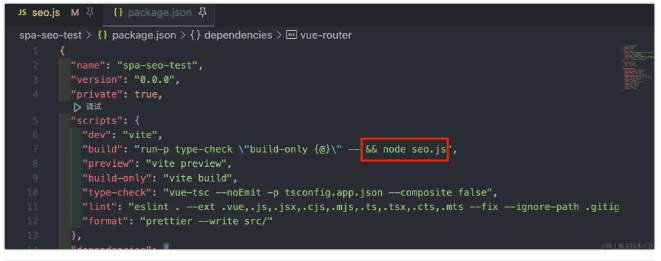
然后在命令行中运行 npm run seo 即可。
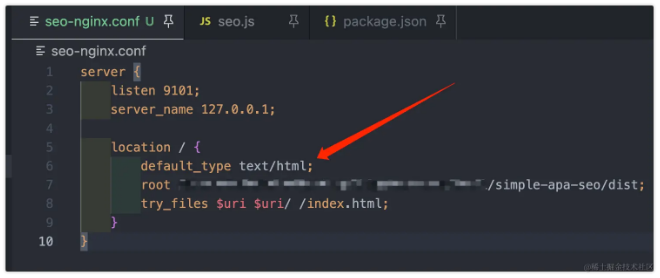
添加 Nginx 配置,使用 default_type text/html; 使无后缀文件以 HTML 类型返回。
这样,你就可以简便地配置和运行 SEO 脚本,同时通过 Nginx 配置确保无后缀文件以正确的 HTML 类型返回。
源代码
/* eslint-disable prettier/prettier */
const fs = require('fs');
const path = require('path');
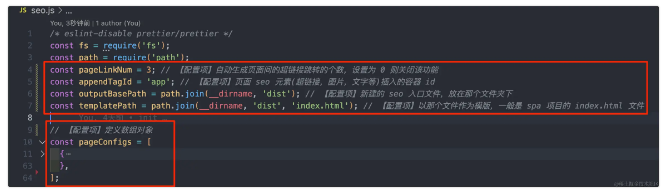
const pageLinkNum = 3; // 自动生成页面间的超链接跳转的个数,设置为 0 则关闭该功能
const appendTagId = 'app'; // 页面 seo 元素(超链接,图片,文字等)插入的容器 id
const outputBasePath = path.join(__dirname, 'dist'); // 新建的 seo 入口文件,放在那个文件夹下const templatePath = path.join(__dirname, 'dist', 'index.html'); // 以那个文件作为模版,一般是 spa 项目的 index.html 文件
// SEO 参考资料:https://github.com/madawei2699/awesome-seo/blob/main/README_CN.md
// 定义数组对象
const pageConfigs = [ {
// 参考资料:https://developers.google.com/search/docs/crawling-indexing/url-structure?hl=zh-cn path: '/m3u8-downloader/index.html', // 访问链接 // 页面标题:搜索引擎通常显示页面标题的前 55 至 60 个字符,超出此范围的文本可能会丢失 // 参考资料:https://developers.google.com/search/docs/appearance/title-link?hl=zh-cn // 参考资料:https://developer.mozilla.org/en-US/docs/Web/HTML/Element/title#page_titles_and_seo title: 'm3u8 downloader', // 页面关键字,google 已经弃用该字段 // https://zhuanlan.zhihu.com/p/382454488 // https://developers.google.com/search/docs/crawling-indexing/special-tags?hl=zh-cn keywords: "m3u8 下载工具,毛静文的博客,Momo's Blog", // 页面摘要 // https://developers.google.com/search/docs/appearance/snippet?hl=zh-cn description: '无需后端支持,一个页面即可完成 m3u8 视频下载,遍历下载 ts 碎片,完成 ts 碎片文件整合,生成完整视频文件。', // 页面描述 // 自定插入的图片 img: [ 'https://upyun.luckly-mjw.cn/Assets/blog/m3u8-downloader-121-75.jpeg', 'https://upyun.luckly-mjw.cn/Assets/blog/m3u8-downloader.jpeg' ], // 自定义超链接跳转 // 参考资料:https://developers.google.com/search/docs/appearance/sitelinks?hl=zh-cn link: [{ text: '点击这里跳转', href: '/tool-show/nginx-online-config-debug/index.html', }], // 自定义插入的标签 content: [{ tag: 'h1', text: '特大视频原格式下载,边下载边保存,彻底解决大文件下载内存不足问题', }, { tag: 'div', text: '推荐一个 m3u8 网页版提取工具,无需下载软件,打开网站即可下载,自动检测,一键下载。', }], // 自定义插入的 html // 参考资料:https://zhuanlan.zhihu.com/p/391844443 html: ` 页面加载中,请耐心等待... <h1 style="white-space: pre;"> 推荐一个 m3u8 网页版提取工具,无需下载软件,打开网站即可下载,自动检测,一键下载。 工具链接:https://blog.luckly-mjw.cn/tool-show/m3u8-downloader/index.html 工具教程:https://segmentfault.com/a/1190000021847172?_ea=32289224 <img src="https://upyun.luckly-mjw.cn/Assets/blog/m3u8-downloader-121-75.jpeg" alt="m3u8 视频下载工具" title="logo"/> <a target="_blank" href="https://blog.luckly-mjw.cn/tool-show/m3u8-downloader/index.html">点击跳转</a> </h1> `, }, ];// 生成页面间随机页面跳转pageLinkNum && pageConfigs.forEach(config => { config.link = config.link || []; const pageLinks = [...pageConfigs]; for (let index = 0; index < Math.min(pageConfigs.length, pageLinkNum); index++) { const pageConfig = pageLinks.splice(Math.floor(Math.random() * pageLinks.length), 1)[0]; config.link.push({ // 自定义插入的标签 text: pageConfig.title || pageConfig.keywords || pageConfig.description, href: pageConfig.path, }) } })const appendTagRegex = new RegExp(`(id="${appendTagId}"[^>]*>)`);const templateStr = fs.readFileSync(templatePath, 'utf8'); pageConfigs.forEach(data => { // 读取目标文件内容 let fileContent = templateStr; // 替换 title 标签 if (data.title) { fileContent = fileContent.replace(/<title>.*<\/title>/, `<title>${data.title}</title>`); } // 替换 meta name="keywords" 标签 if (data.keywords) { fileContent = fileContent.replace(/name="keywords"[^>]+/, `name="keywords" content="${data.keywords}"`); } // 替换 meta name="description" 标签 if (data.description) { fileContent = fileContent.replace(/name="description"[^>]+/, `name="description" content="${data.description}"`); } // 插入自定义 html 标签 if (data.html) { fileContent = fileContent.replace(appendTagRegex, `$1\n${data.html}`); } // 插入 content 标签 if (data.content) { const contentTags = data.content.map(contentConf => typeof contentConf === 'object' ? `\n<${contentConf.tag}>${contentConf.text}</${contentConf.tag}>` : `\n<div>${content}</div>`).join(''); fileContent = fileContent.replace(appendTagRegex, `$1${contentTags}`); } // 插入 a 标签,设置超链接跳转 if (data.link) { const aTags = data.link.map(linkConf => `\n<a target="_blank" href="${linkConf.href}">${linkConf