ChatGPT的广泛应用再次突显了数据的不可或缺性。它之所以能够如此全面地应对各种任务,得益于其对互联网海量数据的学习和训练,形成了一个强大的语言模型。在人工智能时代,数据的价值愈发凸显,掌握有价值的数据成为话语权的关键。
对于普通人而言,我们每天都在接触各种数据。在做出重要决策之前,比如进行行业调研,通常需要获取大量的数据并进行深入分析。这正是数据驱动时代的典型体现。
虽然在以往,爬取大量数据通常需要具备一定的编程技能,例如Python是广泛应用于数据抓取和分析的编程语言。然而,随着ChatGPT的出现,即使不懂编程的人也能通过与ChatGPT对话来完成复杂的数据抓取任务。
本文将通过实际案例详细说明如何利用ChatGPT实现无代码的网站数据抓取,让我们一起探索吧。
使用ChatGPT进行数据抓取的前提条件
为了进行网站数据抓取,首先要确保设备联网。众所周知,没有插件的ChatGPT是无法直接进行网络访问的。为了解锁此功能,用户需要成为ChatGPT Plus会员。成为Plus用户有以下几项好处:
即使在高峰时段,也能获得流畅的访问体验。
可使用更高能力的GPT-4。
有机会优先体验ChatGPT的最新功能。
能够安装插件商店中的任意插件。
如果你对是否升级至ChatGPT Plus存在疑虑,可以参考我的这篇文章:
如果你已经是ChatGPT Plus会员,但不知道如何安装下文要介绍的插件,可以查看我这篇文章:
接下来,我将展示如何使用ChatGPT进行一个实际的网站数据抓取任务。我们选取了一个常用于爬虫教学的网站,该网站共有10页,每一页包含若干名人的名言。
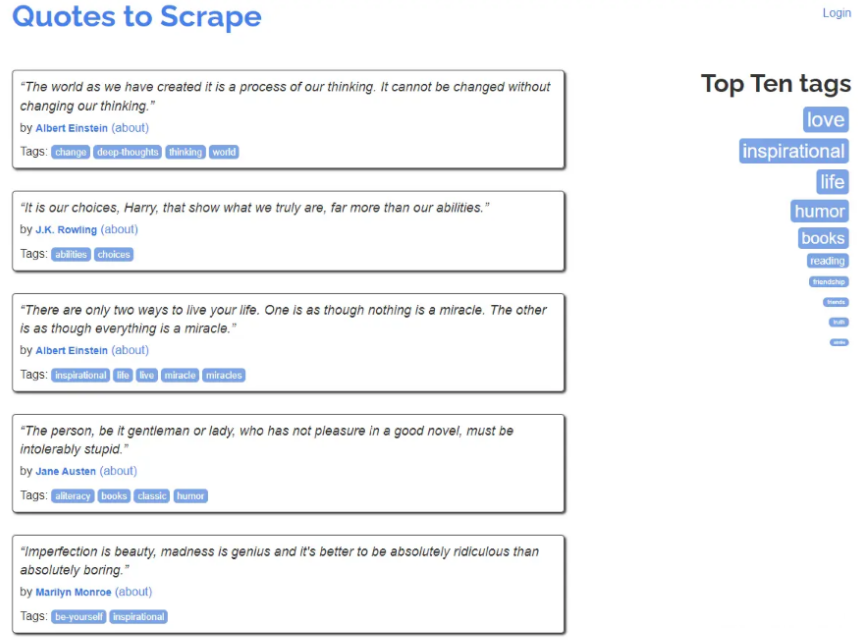
我的任务是让ChatGPT爬取每一页的名人名言,并将这些名言、作者以及标签的数据存储到一张表格中。下面我将介绍两种方法,第一种适用于小型项目,第二种适用于大型项目。
使用 Scraper ChatGPT 插件进行数据抓取
激活了ChatGPT的插件功能后,打开插件商店并搜索"scraper"。
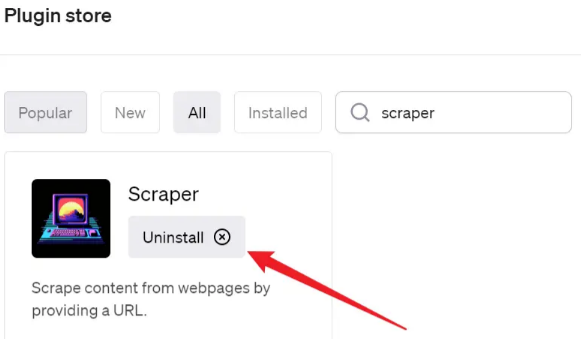
找到该插件后,点击"Install"按钮进行安装。如果已安装,按钮将显示"Uninstall"。
激活了 Scraper 插件后,我提交了以下Prompt给ChatGPT:
请从网站 quotes.toscrape.com/ 抓取数据,并从每个页面提取以下信息:页面编号、名言、作者、标签。另外,请通过定位“下一页”按钮导航到下一页并重复此过程。在抓取所有数据后,请以表格格式整理它们。请以表格形式提供最终输出结果,而无需解释过程中涉及的步骤。
在这个Prompt中,我首先告知ChatGPT要爬取的网站以及要保存的字段。然后,我明确告诉ChatGPT要点击下一页并重复这个过程。考虑到输出字数受限,我指示ChatGPT只输出表格,无需解释完成任务的过程。
最终,ChatGPT生成了包含100行数据的表格。由于字数限制,它分为3-4次才输出完整的表格,但在每次输出时我只需点击继续按钮即可。下图展示了完整的输出。
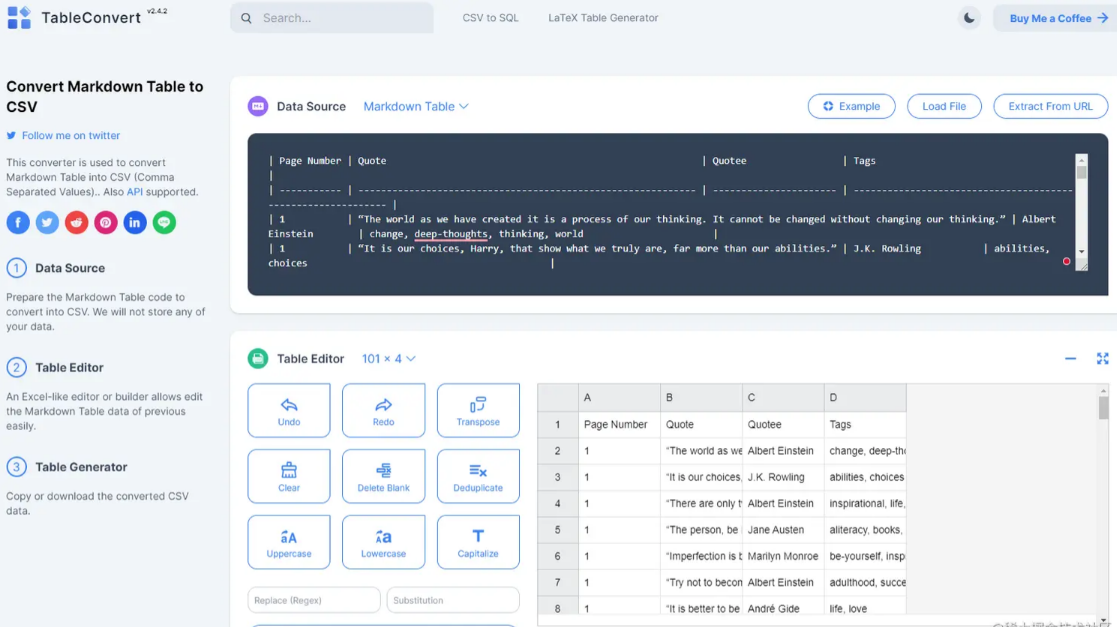
如果输出数据较少,可以直接复制粘贴到Excel中,也可以结合其他能够输出CSV表格的插件,如A+ Doc Maker或CSV Exporter,将结果直接保存到CSV文件中。但由于我要输出的数据超过了这两个插件的限制,无法生成CSV。
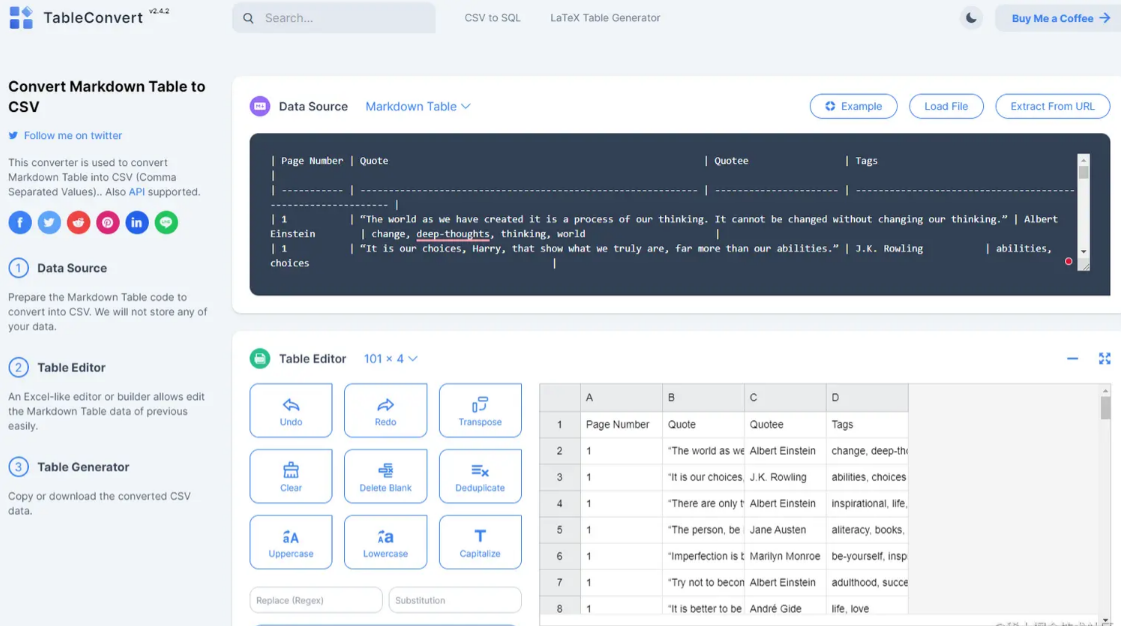
因此,我选择使用在线转换工具将其转换为CSV表格。
你也可以使用 Code Interpreter 进行转换。
👉 ChatGPT代码解释器:1分钟处理1000份文档,高效而强大
使用 Noteable ChatGPT 插件进行数据抓取
之前,我曾撰写一篇专门介绍如何使用 Noteable 进行数据分析的文章,强调其在大型爬虫项目中的卓越表现。
👉 Noteable ChatGPT插件:颠覆数据分析的全新力量
与之前安装 Scrape 插件的步骤相似,你只需在插件商店中搜索 "noteable",找到插件后点击 "Install" 进行安装。
安装完成后,将弹出一个登录界面。创建一个免费账户并登录后,你将拥有一个独立的Noteable云空间。这个云空间独立于ChatGPT,ChatGPT输出的所有代码和文件都存储在你的云空间中。因此,你无需像之前的方法那样先输出Markdown表格,再转化成Excel或CSV。

这种方法特别适用于大型项目。想象一下,如果你需要爬取几万行的数据,输出到ChatGPT可能会超过其字数限制,迫使ChatGPT必须分多次输出。而Noteable直接通过代码爬取网站并将数据直接生成所需的文件。
我将上述任务交给Noteable执行,提交了如下Prompt:
创建一个名为 "Web Scraper" 的项目,并抓取网站 quotes.toscrape.com/。从每个页面获取以下信息:页面编号、名言、作者、标签。另外,请通过定位“下一页”按钮导航到下一页并重复此过程。在抓取所有数据后,请以表格格式整理并保存为 "quotes.xlsx"。
Noteable按照项目组织任务,一个项目包含代码和文件。当我让ChatGPT创建一个名为“Web Scraper”的项目时,它在Noteable的云空间中生成了相应的项目。
任务完成后,我看到项目中有两个文件。web_scraper.py是ChatGPT帮我自动生成的笔记本,记录了爬虫的代码。
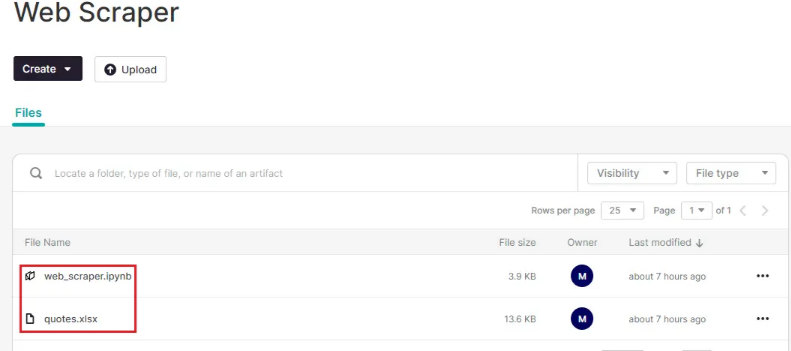
quotes.xlsx是从网站上爬取的数据,直接在Noteable中下载即可。

即使网站有几万页,Noteable的处理速度也很快,因为它的计算资源是独立于ChatGPT之外的。如果成为Noteable的付费用户,还可以使用更高配置的计算资源:
Medium: 2 vCPU, 7.5 GB 内存
Large: 4 vCPU, 15.0 GB 内存
Extra Large: 7.5 vCPU, 29.0 GB 内存
Small (GPU): 2 vCPU, 10.0 GB 内存
Medium (GPU): 6 vCPU, 26.0 GB 内存
本文介绍了两种不同的方法,各自具有优劣之处。
使用 Scrape ChatGPT 插件操作简便迅速,无需额外注册第三方平台账号,所有步骤均在 ChatGPT 中完成。然而,受限于 ChatGPT 本身的字数限制,目前尚无法与其他插件直接合作,将大量数据直接输出到文件。
相反,使用 Noteable 则能摆脱 ChatGPT 的限制,将爬取的庞大数据直接保存在 Noteable 平台中,但需要创建免费 Noteable 账号,并在平台执行一些基础操作。
总的来说,无论选择哪种方法,ChatGPT都大幅降低了爬取网站数据的门槛,使得不懂代码的人也能轻松应对海量数据。在以往的爬虫过程中,需要通过代码指定元素位置,例如翻页按钮或要爬取字段的位置。而现在,只需告诉 ChatGPT 所需字段并执行翻页,它就能智能识别元素位置,这带来了极大的便利。