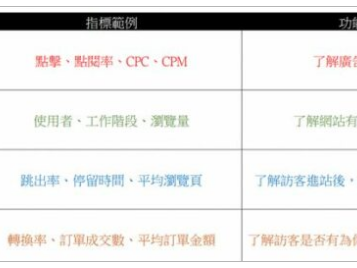
在之前文章中,我介绍了搜索引擎的基本运作原理,包括检索与索引的区别。
本文假设你已经对检索与索引有了基本认识,并将向你介绍如何利用meta robots和robots.txt来优化Google的检索与索引。如果你对这些概念还不熟悉,建议先阅读我的上一篇文章。
meta robots与robots.txt的作用
meta robots和robots.txt都是用于阻止Google检索或索引你的页面的工具。如今,仅仅追求SEO排名和高流量是不够的,流量必须对企业产生价值,必须能够转化为实际效果。因此,用户体验变得相当重要。如果你有特定页面可能影响用户体验(UX),你可以通过这些方式阻止该页面在Google搜索结果中显示。

robots.txt可以阻止搜索引擎检索你的数据。如果你使用robots.txt来阻止搜索引擎,它将会跳过你所阻挡的页面,不进行检索。
与此不同,meta robots在索引层面阻止搜索引擎索引你的页面,但Google仍会爬取你的网站数据。接下来我将详细解释为何我们要这样做。
▍学习使用Robots.txt
通常情况下,我们不会使用robots.txt来阻止搜索引擎检索我们的网站,除非你确定这个页面对SEO有负面影响。如果你有页面不希望出现在搜索引擎中,我建议使用Meta Robots来控制索引,让Google仍然可以检索网站数据。但如果你确定这些页面会影响SEO并且你不希望Google检索到它们,你就要使用Robots.txt。(比如说正在开发中但还没完成的网页)
要使用robots.txt文件很简单,只需创建一个名为robots.txt的文本文件,并上传到你的网站根目录中。在这个文件中写上你希望Google不要抓取的页面路径。
例如,在www.yesharris.com的根目录下,我上传了这个文件,并且我不希望搜索引擎抓取我的后台登录页面,所以我在文件中写下了Disallow:/wp-admin/。
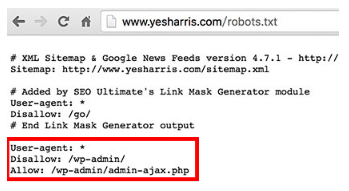
基本上,在robots.txt文件中,你只需要填写以下信息:
User-agent:填入搜索引擎蜘蛛的值(*号代表全部)
Disallow:填入你希望搜索引擎不检索的页面路径
Allow:如果你禁止检索的页面路径里又有特定路径你希望搜索引擎检索,则填入
▍学习使用Meta Robots
要使用meta robots,只需将其直接添加在<head>标签内。你必须在“你不希望被索引的页面”下,将这个标签添加到<head>标签中。
所以如果你有六个页面不希望被索引,那么你需要手动在这六页中加入meta robots。
meta robots的标签形式如下:
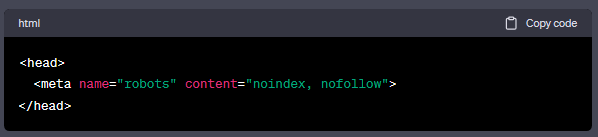
这个标签有两个属性:noindex和nofollow。
当你不希望搜索引擎索引此页面时,使用noindex。
当你希望正常索引时,使用index。
关于nofollow,如果你希望搜索引擎在检索此页面时,不进一步检索该页面所链接的其他页面,那么使用nofollow。这通常用于社群论坛或讨论版,以防止乱贴链接的情况发生。
两者的功能完全不同。接下来我将举几个例子,让你完全了解如何使用。
<meta name="robots" content="noindex, nofollow">
这告诉搜索引擎不要索引我的网站,同时不要检索与该页面相关的链接。
<meta name="robots" content="index, nofollow">
在检索资料时,不要检索该页面相关的链接。
<meta name="robots" content="noindex, follow">
不要索引我的页面,但页面上的所有链接请正常检索(最常用的方式之一)。
<meta name="robots" content="index, follow">
这个标签没有任何意义,与不加标签的效果相同,相当于搜索引擎将正常索引和检索。
▍何时使用robots.txt阻止Google检索?
对于检索优化的工作,你的网站必须让Google能够理解,并且能够抓取到数据。对于某些动态页面结构,可能会对网络爬虫的检索造成问题,这一点我在上一篇文章中已经提到。毕竟最遗憾的情况莫过于你的网站有优质内容,但Google根本无法检索到这些数据。虽然Google的网络爬虫通常是市场上效率最高的,但与DuckDuckGo、Bing、百度等搜索引擎相比,它们的效率可能并不如Google出色。因此,我们必须时刻关注搜索引擎的检索情况。
但是,有些页面和内容你可能不希望Google检索到。这时,你必须使用Robots.txt来阻止Google蜘蛛的检索。这也是我们今天讨论的重点。接下来我们来看看,在什么情况下你会希望Google蜘蛛不要检索你的网站。
未完成的页面
如果你有一些页面正在技术人员开发中,但完成时间还需要很长一段时间,甚至你还需要进行修改和测试,那么这些未完成的页面通常不会对SEO造成伤害。但你可能不希望访问者在搜索引擎中搜索到这些未完成的页面,因为这些页面会给用户带来较差的使用体验。
测试页面
有时工程师为了进行功能测试会开设一个测试用的子域名,并上传与主域名完全相同的内容。正如我在《理解Google Panda:网站内容对SEO的影响》一文中提到的,完全相同的网站内容会对SEO造成伤害。如果你有这样的页面,我建议你将Google蜘蛛阻止在门外。
网站后台及其他理由
比如我个人的网站是用WordPress搭建的,所以我使用robots.txt阻止搜索引擎检索我的网站后台。搜索引擎检索到后台的登录页面对SEO没有伤害,但也没有任何帮助。如果你根本不希望搜索引擎检索你的网站,我也建议你使用robots.txt来阻止搜索引擎的检索。
▍何时使用meta robots阻止Google建立索引?
如果你希望某些页面不被用户在搜索引擎中找到,但这些页面实际上对SEO排名有很多加分因素,那么你可能希望Google检索这些页面的数据,但不要将其索引到搜索引擎中。这时,你就需要使用meta robots来阻止Google索引你的页面。
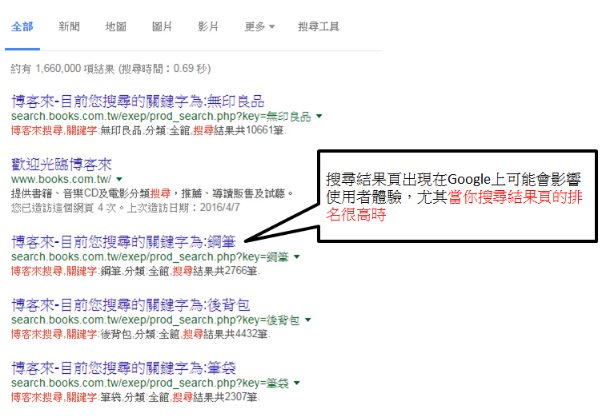
举个例子:
示例A:
假设我在我的博客的“搜索结果页”上使用了meta robots来阻止Google索引这些页面。因为如果新用户从搜索引擎跳转到旧用户搜索过的页面,这可能会给新用户带来负面的用户体验。但我的搜索结果页有很多人分享、有很多反向链接,也有很多流量,这些都对我的SEO排名有帮助。我希望Google检索这个页面,知道我的网站有很多分享、反向链接。所以我使用了meta robots来禁止Google索引我的搜索结果页,但Google仍然可以爬取这个页面的数据,对我的整个网站的SEO排名有帮助!
示例B:
如果我经营一家书店的电子商务网站,用户在登录会员之前就可以使用购物车,但我不希望用户的购物车页面被Google索引进搜索引擎,这时我会使用meta robots来阻止搜索引擎进行索引。
需要注意的是,Google官方明确表示,meta robots和robots.txt确实可以告诉Google你希望哪些页面不被检索和索引,但Google也会尊重你的决定(毕竟你是网站拥有者)。但Google官方不能保证搜索引擎会完全遵守meta robots和robots.txt的规定。如果搜索引擎认为你的网站有很多反向链接、流量很高、内容很优质,是优质网站,他们也有可能执意要检索和索引你的网站。
通过了解meta robots和robots.txt,你可以优化网站的检索与索引情况,阻止特定页面被检索或索引。但要注意,官方声明了它们可以指示搜索引擎不检索和索引哪些页面,但并不能保证搜索引擎完全服从。若搜索引擎认为你的网站是优质网站,它们可能会坚持检索和索引。