
爬取(Crawl)与索引(Index)是SEO领域中极为基本的两个观念,在学习SEO前务必理解这两者的基本概念。然而,爬取与索引的优化相当庞大,单一篇文章难以涵盖所有细节,因此本文将仅针对基础概念进行解说,并在文章中提供相关连结,以协助您进一步学习。
Google也提供许多官方的HTML语法供网站经营者使用。透过这些语法和HTML标记,您可以优化搜寻引擎的爬虫如何爬取和理解您的网站。每一种语法的功能各异,因此我将逐篇独立撰写相关文章,例如:
三分钟搞懂SEO的《meta robots、robots.txt》
认识SEO排名的杀手,『重复內容』超完整攻略
(此篇提到的Canonical标记是常用的SEO标记之一)
在阅读上述文章之前,建议您先完整瞭解「爬取(Crawl)」和「索引(Index)」的概念。
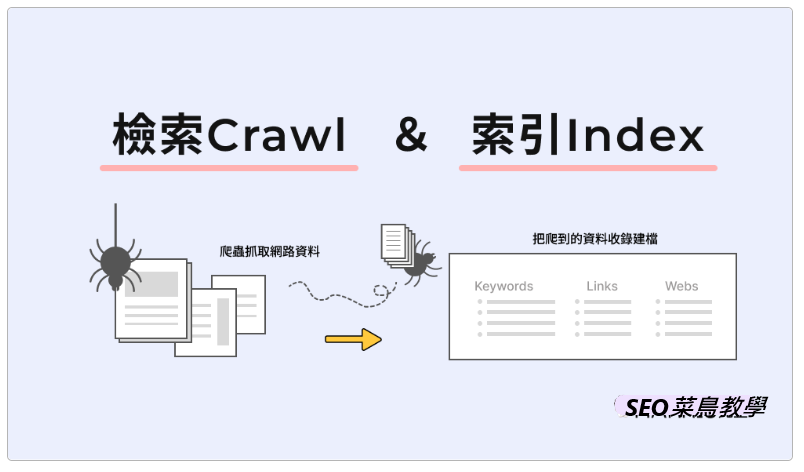
理解SEO的『爬取』與『索引』
网路爬虫这个概念相对抽象,Google官方称之为Google Spider或Google Bot。您可以将整个网际网路想像成一张庞大的蜘蛛网,而每个搜寻引擎都拥有自己的爬虫程式,这支程式会像蜘蛛一样在网路中爬行,并收集相关资讯。
对于SEO工作者而言,维护良好的搜寻引擎爬虫与网站之间的关係至关重要。我们必须尽量确保爬虫能完整爬取您网站上的高品质内容。否则,将会影响您的网站SEO成效(我将在后续文章中详细讨论此议题)。搜寻引擎运作塬理可简单分为叁个阶段:
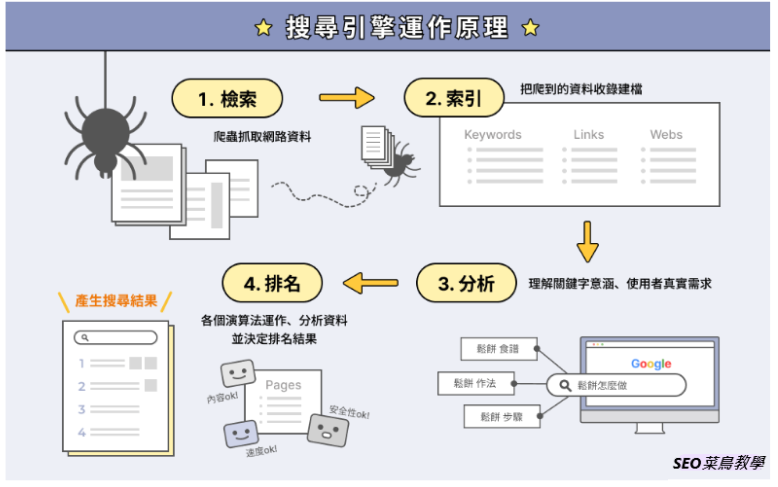
阶段1 – 爬取(Crawl):搜寻引擎的爬虫会访问您的网站,爬取并下载所有可取得的网页资料。虽然Google官方文件正式使用「检索」这个名词,但SEO业界较习惯以白话的方式称之为「爬取」或「抓取」。在此阶段,Google的爬虫将收集网页内容、程式码、图片等所有网页相关资讯。
阶段2 – 索引(Index):这指的是将您网页的资讯收录并建立索引,使其能在搜寻引擎中被找到。然而,网站被收录进搜寻引擎并不代表您的网站将获得丰富的搜寻流量。Google或许愿意收录您的网站,但未必愿意给予优越的搜寻排名(这取决于您的网站是否优质,以及是否进行了良好的优化)。因此,被Google收录是重要的第一步,若Google连您的网站都不愿意收录,那么SEO和搜寻流量将无法谈。
阶段3 – 分析搜寻意图:Google透过演算法来理解使用者搜索的「关键字」的意义,以及使用者真正需要的资讯起。
阶段4 – 曝光在搜尋結果:当搜寻者输入关键字时,您的网站可能被Google呈现给搜寻者,进而为您的品牌带来搜寻流量(前提是您的网站是优质的,并进行了适当的SEO优化)。
为何理解『爬取』和『索引』对于学习SEO至关重要?
在实际操作中,我们会遇到许多网路文章专注于所谓的「排名因素」,即如何优化您的网站,使其在搜寻结果中获得较高排名。然而,实际上网站会面临许多不同方面的SEO问题,取决于网站的结构、所属产业、所在市场等各种因素,单靠优化「排名因素」并不足够。如果Google无法正常爬取您的网站资料,再优化排名因素也无济于事,因为Google爬虫根本看不到您网站的内容。因此,了解搜寻引擎的爬虫如何进行爬取和索引是至关重要的。
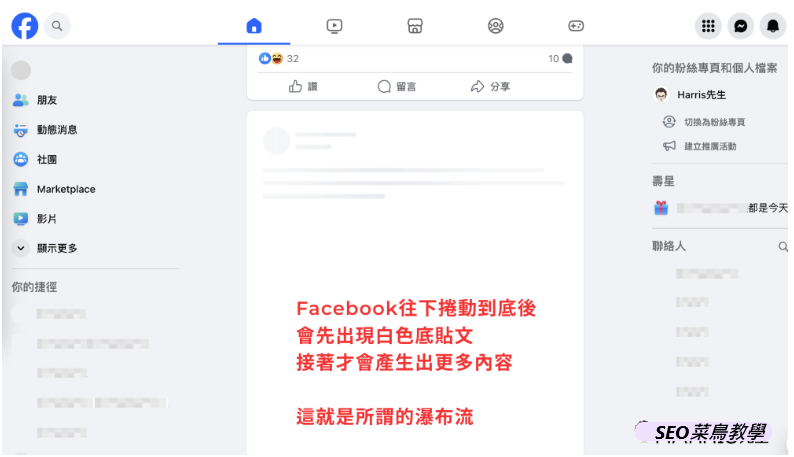
举例来说,我们常遇到客户网站使用AJAX技术构建动态瀑布流的情况。当您进入网站时,会看到首批文章连结,随着滑鼠向下滚动,程式会触发,显示后面的文章(类似Facebook目前的做法,称为瀑布流)。
通常在这种情况下,Google爬虫只会爬取首批文章,因为爬虫无法像人类使用者一样进行下滚操作,也无法触发AJAX程式。在这样的案例中,Google爬虫看到的网页信息很有限,这也会影响您的SEO(无论您的网站有多优秀,如果Google爬虫无法有效看到内容,将无法发挥作用)。
因此,作为一名SEO专业人士,研究并了解爬虫的效能至关重要。我们必须了解不同搜索引擎的爬虫有哪些效能限制,以及哪些网页技术可能会妨碍爬虫进行有效爬取。Google的爬虫、Bing/Yahoo搜索引擎的爬虫也由不同的团队/公司开发,因此它们的效能也会略有不同。如果您希望在SEO时不仅考虑Google,还希望优化Yahoo/Bing,则需要花时间研究各自的特点。
如何确定爬取和索引状况是否有问题?
这是一个涵盖多方面的议题,在这篇文章中,我将先讨论一些基本概念和方法。
首先,只要Google能够正常且有效率地「爬取」您的网站,通常索引状况就不太会有问题。一般情况下,如果Google能够健康地爬取您的网站但却未收录,这可能意味着您的网站可能违反了Google的政策,并因此受到处罚(除非违反政策,否则Google一般会尝试收录网站)。因此,检查Google是否正常爬取您的网站的方法之一就是通过Search Console报告(见下图範例)。
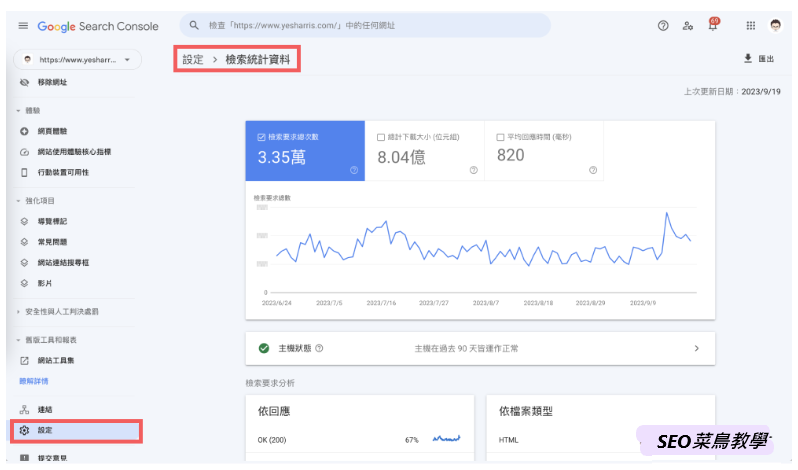
在Search Console的「设定>检索统计资料报表」中,您可以查看每天爬取的网页数量。该图表代表Google每天爬取的网页数量。通常情况下,这个数字会在一个範围内波动,Google每天能够爬取多少网页取决于多个因素,包括您的网站在市场上的重要性、网站的SEO权重等。
例如,如果Google决定给予您的网站每天10分鐘的额度,那么他每天只会来爬您的网站10分鐘,之后便会离开。因此,如果您的网站速度优化得越好,爬虫在相同的10分鐘内能够爬取的网页就越多。
然而,「索引」方面呢?如何确认Google是否健康地索引了我的网站?
您可以通过Search Console的网页索引报表查看Google已经建立索引的网页数量,同时也会清楚列出未被索引的网页以及相关塬因。
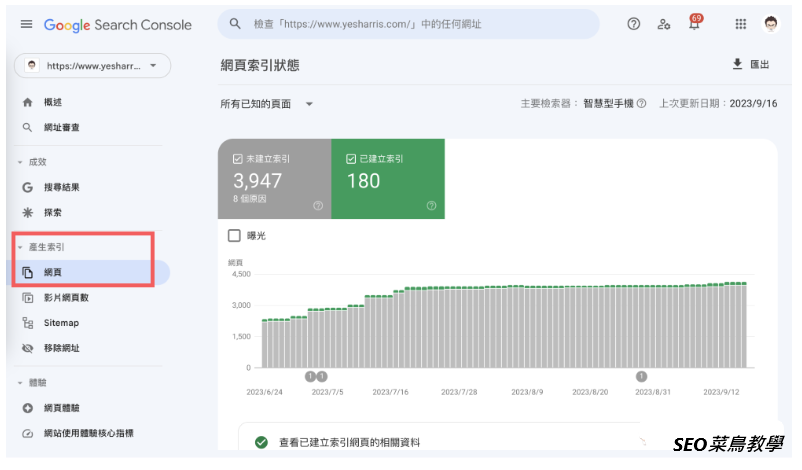
这部分的详细说明,您可以参考这篇学习使用Site指令,诊断Google索引状况,其中包括了非常完整的教学。
在SEO方面,如何避免出现「爬取」和「索引」问题?
除非您的网站存在违规或作弊行为导致Google不愿意处理您的网站,否则您需要注意以下一些优化项目,这也是我们通常在担任SEO顾问时会检查的优化项目:
尽量避免过度使用对Google不友善的AJAX技术,尤其是在重要的网页或内容上。
尽可能优化您的网站速度,以确保爬虫在有限的时间内能够爬取尽可能多的网页。
避免重复内容问题,特别是避免网址参数造成的重复内容。
确保网站没有损毁或坏掉的网页,避免不必要的转址。
如果产品/文章已下架,请及时将相关连结从网站上移除,以免浪费爬取额度。
这些建议是我们在SEO优化时经常会考虑的重点,也是确保爬取和索引状况良好的关键因素。希望对您有所帮助!











