在今天快节奏的社会中,有效地处理和转换文档对于提高生产力和实现高效工作流程至关重要。然而,处理各种文档格式、提取有价值信息以及执行批处理操作的复杂性可能让人望而生畏。
ChatGPT的Code Interpreter(代码解释器)是一个极为强大的多功能工具,使用户能够轻松简化与文档相关的任务。无论是处理PDF、合并和分割文件、提取表格和图像、用密码保护敏感文档、总结内容、生成引人入胜的词云、执行OCR识别,还是转换文件格式,Code Interpreter都能游刃有余。
现在,让我们一同探索一些实际案例,了解它是如何改变我们与文档互动的方式。
批量处理文档
文档作为信息的载体,在日常办公中经常需要进行处理。高效处理文档是提高生产力的重要环节。代码解释器让您能够一次性上传并批量处理多个文档,极大地提高了我们的生产效率。这个功能使得处理大量文档变得轻而易举。
PDF水印批量处理
添加水印是一种广泛应用的做法,尤其在专业和商业领域。众多组织,包括公司、教育机构、政府机关和内容创作者,选择在PDF文档中加入水印,以维护内容的安全性、保持所有权并巩固品牌标识。
通过Code Interpreter,您可以轻松实现对PDF进行批量水印处理,只需一个简单的Prompt:"请在所提供的ZIP文件中找到的多个PDF的每个页面中心添加对角线水印。水印应按目标页面大小的75%进行缩放,水印内容为“myaiforce.com”,采用Courier-Bold字体书写,颜色为灰色,透明度设置为50%。任务完成后,请分享所有已处理PDF的下载链接。"
我使用Code Interpreter生成了5个PDF并将它们压缩成一个ZIP文件,作为演示示例。然后,我将文件上传到代码解释器,并输入了上述Prompt。

在经过一系列步骤后,代码解释器为每个PDF的每一页都添加了符合指定要求的水印。

值得注意的是,除了指定文本内容进行水印添加外,您还可以上传公司logo图片作为水印,或者在PDF结尾处添加个性签名,以满足更多个性化需求。
这一批量处理PDF水印的功能为用户提供了更便捷、高效的方式来保护文档内容和维护品牌标识。
PDF合并与拆分:高效管理文档
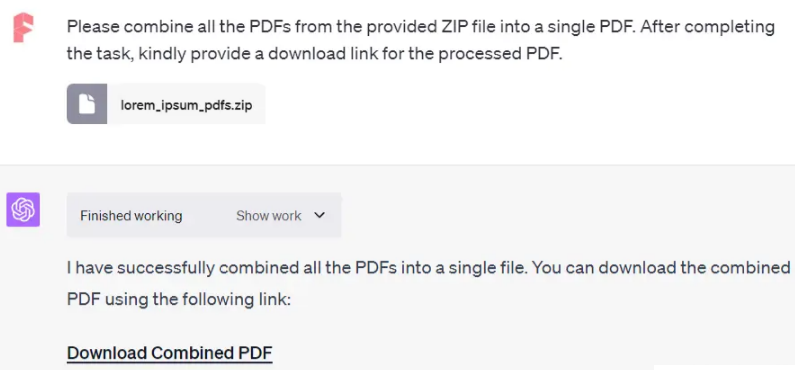
将多个相关的PDF文件合并成一个文件既方便存储又便于查看。在上述例子中,合并多个PDF只需输入以下Prompt:
"请将所提供的ZIP文件中的所有PDF合并为一个PDF。完成任务后,请提供处理后的PDF的下载链接。"
ChatGPT迅速完成了合并任务。
除了合并功能外,Code Interpreter当然也轻松应对PDF拆分的需求。
合并和拆分PDF是Code Interpreter的另一个强大功能。用户可以便捷地通过简单的指令实现将多个PDF整合成一个文件,或者按需将PDF拆分为更小的单元。在上述案例中,ChatGPT通过用户提供的Prompt完成了多个PDF文件的合并操作。
这个功能不仅仅是在存储和管理文档方面提供了高效的解决方案,同时也增强了用户对文档的灵活性和控制力。在数字化的时代,这样的工具成为了提高工作效率和整理文档的不可或缺的帮手。
PDF表格与图片提取:数据处理得心应手
从PDF中提取表格不仅使数据分析和可视化更加轻松,而且可以将提取的表格转换成Excel文件以进行更深入的处理。
使用Code Interpreter执行这项任务的Prompt非常简单:
"请从PDF中提取表格并将其另存为Excel文件。让我们一步一步来。完成任务后,请提供Excel文件的下载链接。"
在第一次尝试中未成功时,我添加了一句"让我们一步一步来",这似乎是激活成功的魔法句子。如果你在使用ChatGPT时遇到输出不稳定的情况,可以尝试添加这句话。
我要提取的PDF中包含一个表格:
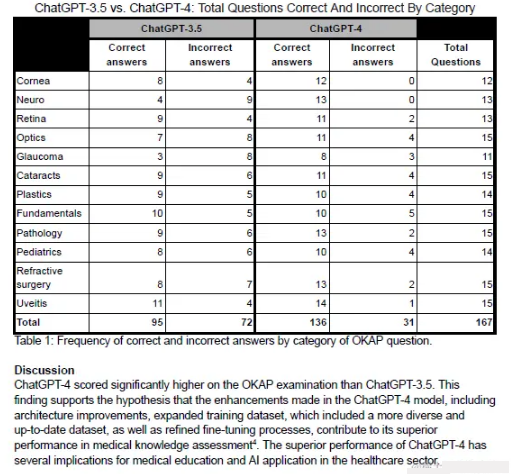
最终由ChatGPT生成的表格稍有不同
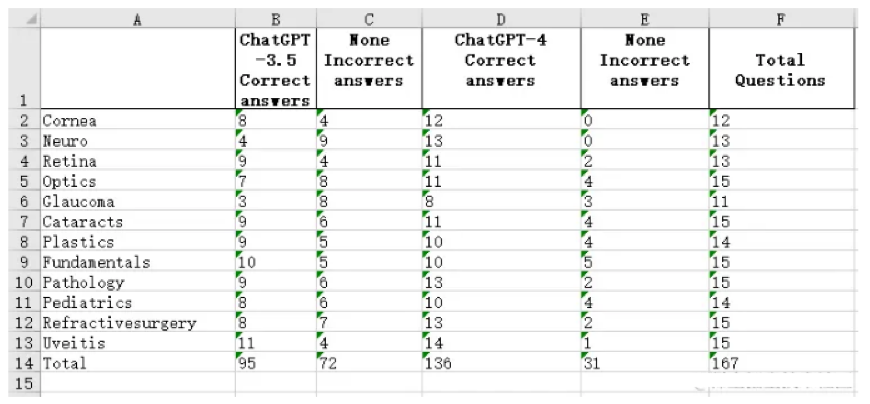
因为原表格存在合并单元格,如果原表格没有合并单元格,输出结果应该与原表格一致。
提取了表格后,我们可以通过Code Interpreter进一步分析数据或绘制图表。之前的文章中已专门介绍了如何使用Code Interpreter分析数据。
原PDF还包含一张图片,内容是一个柱状图。我们同样可以通过Code Interpreter提取出来。只需将以下简单的Prompt提交给ChatGPT:
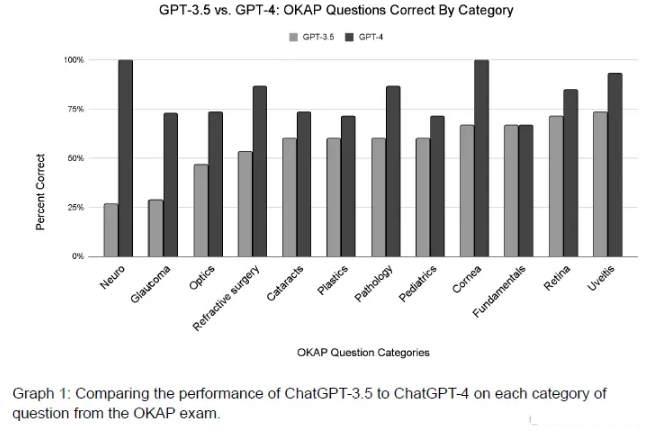
"请从PDF中提取图像。让我们一步一步来。完成任务后,请提供图像的下载链接。"
这一演示只使用了一个PDF,实际上Code Interpreter的强大之处在于批量处理。你可以将多个PDF压缩成一个包,然后上传到ChatGPT进行批量提取。同时,它也支持提取其他文档中的表格和图片,比如Word文档。
这一功能为用户提供了更多灵活性,无论是在数据处理还是文档提取方面。
PDF密码保护:确保敏感信息安全
通过为PDF添加密码,可以有效确保只有授权人员能够访问PDF的内容,从而降低数据泄露的风险。这是一种保护敏感信息的重要手段。
为PDF添加密码保护只需一个简单的Prompt:
"在此PDF中添加密码(yU5NIK5Y)。完成后,请提供下载链接。"
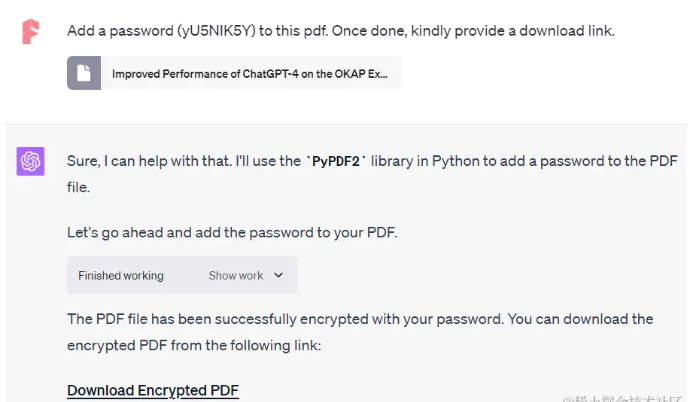
你也可以同时为多个PDF添加密码,但务必记录好密码。此外,除了PDF,你还可以对其他文档类型如Excel、Word等进行加密。
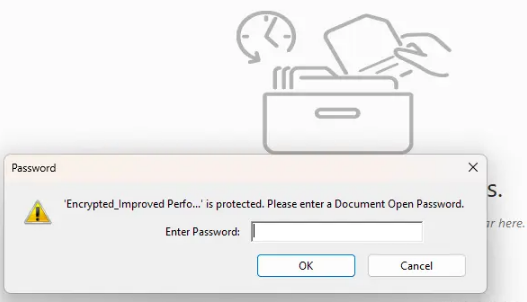
这项功能提供了一种简便而高效的方式,帮助用户更好地保障文档的安全性,特别是对于包含敏感信息的文件。无论是单个文件还是批量操作,都能在保护文档隐私方面发挥作用。
PDF内容概要:ChatGPT智能总结
ChatGPT提供了多种方法来智能总结PDF内容,其中使用Code Interpreter是其中之一。其最大优势在于可以批量处理多个PDF,将总结生成的内容保存为Excel文件,更便于查阅。
为了演示方便,我上传了一个PDF并提交了以下Prompt:
"用三句话总结此PDF。让我们一步一步来。"
ChatGPT的处理过程如下:
ChatGPT先阅读PDF内容,提供一个初步的摘要,同时指出提取的文本中可能包含重复信息,可能是由PDF元数据、页眉和页脚引起的。
ChatGPT进行文本清理以删除重复短语,但仍然注意到清理后的文本中可能存在来自页眉或页脚的重复信息。
ChatGPT试图使用pdfplumber库再次提取文本,最终获得了清晰、连贯的文本,包括标题、作者、所属单位和摘要的开头。
ChatGPT尝试使用Transformers库进行文本摘要,但由于当前环境限制,未能实现。然后,ChatGPT提供了手动摘要,涵盖了文件的主题、作者、研究内容以及对性能比较的初步结果。
总的来说,ChatGPT通过不断优化处理过程,提供了对PDF内容更准确的概要。这个功能对于快速获取文档核心信息非常有帮助。
PDF文本词云生成:深度挖掘关键概念
利用词云生成技术,我们可以提取文档中最频繁出现的单词,并通过可视化方式快速洞察PDF所涉及的主要概念。通过批量生成词云,不仅能揭示多个PDF文本之间的相似性和差异,还为比较分析和聚类分析提供了有力支持。
我使用如下Prompt为单个PDF生成词云,而Code Interpreter同样可以为多个PDF文档进行批量词云生成。此外,不仅局限于PDF,还可以对其他文档类型如Word、Markdown、Epub等进行词云生成。
"请从PDF中删除停用词并生成词云。"
这个过程将帮助我们更深入地了解文档中的关键概念,而批量生成词云则在跨多个文档进行深度分析时展现出其强大的分析能力。这项功能为用户提供了更全面的文本分析工具,助力深入挖掘文档内容。

PDF信息提取:精准抓取关键内容
通过上述生成的词云,我们已经了解了PDF中的主要关键词。现在,如果我们想要提取包含特定单词,比如“model”(不区分大小写)的句子,Code Interpreter同样可以轻松胜任。
使用如下Prompt,我们可以一步一步地将包含单词“model”的句子从PDF中提取出来,并将其保存为文本文件。完成任务后,可以提供文本文件的下载链接。
"请从PDF中提取包含单词“model”(不区分大小写)的句子,并将其另存为文本文件。让我们一步一步来。任务完成后,请提供文本文件的下载链接。"
经过PDF的处理,符合条件的句子已经成功提取,并被导出到一个txt文件中,同时提供了下载链接。在结果中,红色方框标记的是前5个提取的句子。
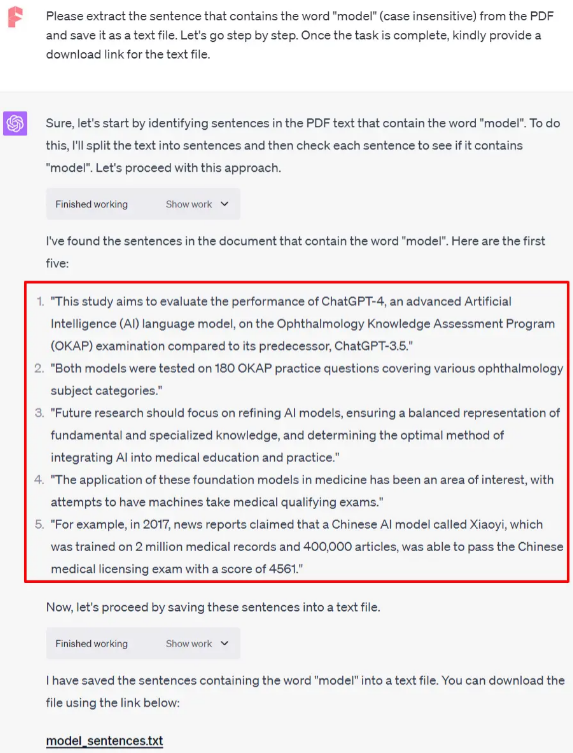
这项功能为用户提供了一个高效的方式,可以精准地从文档中抓取特定关键词相关的信息,为进一步的分析和研究提供了有力支持。
OCR文本识别:赋予PDF更强大的搜索能力
OCR技术的应用能够将扫描的或基于图像的PDF转化为可搜索和选择的文本,使得PDF文档更加便于使用,并显著减小文件大小。对于图像中的文字,OCR技术能够将其准确地转化为文本,为进一步的处理提供了方便。
我选择了一份1972年的信件扫描件,以演示Code Interpreter的OCR识别效果。同时,Code Interpreter支持批量处理多个PDF文件。

通过以下Prompt,我成功应用了OCR技术,将提供的PDF中的文本进行识别,并生成了包含识别文本的新PDF。任务完成后,分享了生成的PDF的下载链接。
"请应用OCR技术来识别所提供的PDF中的文本,并生成包含识别文本的新PDF。完成任务后,请分享生成的PDF的下载链接。"

OCR识别效果良好,生成的PDF保留了准确拼写的文本。这项功能使得PDF文档不仅更易于编辑和搜索,同时也提高了文档的整体可用性。
批量文件格式转换:提升文档可用性
在处理文件时,由于不同应用程序所支持的格式不同,选择最适合特定目的的文件格式变得至关重要。代码解释器为我们提供了批量进行不同格式转换的便捷方式,使得文件在不同系统间更加可用。
以批量将webp格式转换为jpg格式为例,许多从网络下载的图片通常以webp格式呈现。然而,由于某些图片编辑软件无法识别和支持webp格式,因此我们常常需要将这种格式转换为其他通用格式,如jpg。
通过Code Interpreter执行批量转换非常简单,只需将待转换的图片放入一个压缩包并上传,然后使用一个简单的Prompt指导ChatGPT进行转换。
以下是具体的Prompt示例:
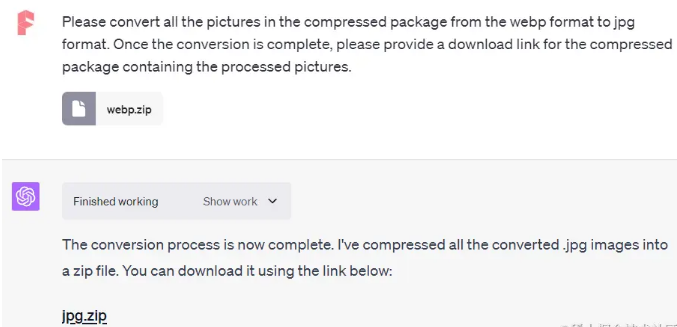
"请将压缩包中的所有图片从webp格式转换为jpg格式。转换完成后,请提供包含处理后的图片的压缩包的下载链接。"
完成转换后,生成的压缩包中将包含所有处理后的jpg格式图片,并提供下载链接。这项功能不仅提高了文件的通用性,同时使得处理和分享文件变得更加便捷。
网页转Markdown及其他格式转换:提升文档灵活性
Markdown作为一种纯文本格式,具有无需网络连接即可轻松打开和阅读的优点。将网页转换为Markdown不仅方便存储,而且在众多笔记应用程序中得到了广泛支持,例如Notion等。
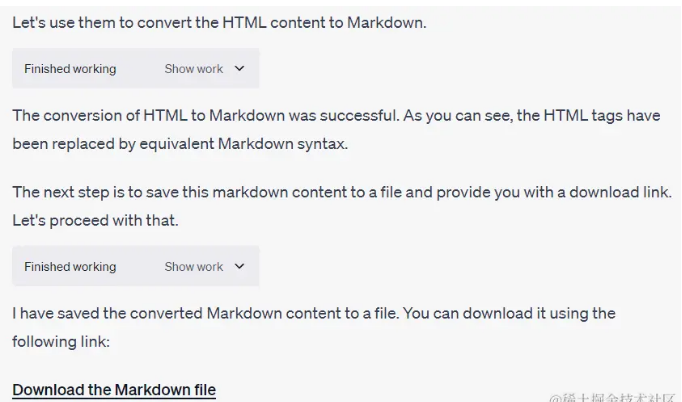
网页转Markdown的过程十分简单。首先,将网页保存为mhtml文件,然后将该文件上传到代码解释器。接着,通过提交以下Prompt给ChatGPT,即可完成转换:
"将此mhtml文件转换为markdown文件。给我一个下载链接。让我们一步一步来。"
此外,Code Interpreter还支持众多其他格式之间的转换,包括但不限于:
压缩格式:7Z、TAR、ZIP、RAR、GZ、BZ2、XZ、LZMA
音频格式:MP3、WAV、FLAC、AAC、OGG、M4A、AIFF、WMA、AMR
文档格式:DOC、DOCX、PDF、RTF、HTML、TXT、ODT、EPUB、CSV、XLS、XLSX、PPT、PPTX、Markdown、LaTeX
表格格式:XLSX、CSV
图像格式:PNG、JPG、JPEG、BMP、TIFF、GIF、SVG、ICO、WEBP、RAW、HEIC、EPS、PSD
视频格式:MP4、AVI、MOV、FLV、MKV、WMV、3GP、WebM、MPEG、VOB
代码文件格式:PY、JS、JAVA、C、CPP、CS、R、Swift、PHP、Ruby、Go、Kotlin、Lua、Shell
数据文件格式:JSON、XML、YAML、SQL、HDF5、PICKLE、Parquet、Protobuf
字幕格式:SRT、ASS、SSA、VTT
字体格式:TTF、OTF、WOFF、EOT
3D 文件格式:STL、OBJ、FBX、COLLADA、3DS、IGES、STEP
地理空间数据格式:GeoJSON、SHP、KML、GPX、GeoTIFF
科学数据格式:FITS、VTK、NetCDF、DICOM
CAD 文件格式:DWG、DXF
电子书格式:EPUB、MOBI、AZW3
电子邮件格式:EML、MSG
网络格式:HTML、CSS、JS、WebAssembly
其他格式:LOG
值得注意的是,虽然代码解释器可以处理这些格式,但转换结果可能取决于使用的特定Python库、文件的复杂性以及格式本身提供的支持。每次转换通常需要根据具体情况进行调整,以确保最佳的转换效果。