引言
搜索引擎的工作过程十分复杂,接下来的三篇文章将简要介绍搜索引擎如何实现网页排名。尽管本文只触及搜索引擎技术的表层,对于大多数SEO从业人员而言,已经足够应用。
搜索引擎的工作主要分为三个阶段:
爬行和抓取: 搜索引擎蜘蛛通过跟踪、发现和访问网页,读取页面HTML代码,并将其存入数据库。
预处理: 索引程序对抓取的页面数据进行文字提取、中文分词、索引、倒排索引等处理,以备排名程序调用。
排名: 用户输入查询词后,排名程序调用索引库数据,计算相关性,最终按一定格式生成搜索结果页面。
预处理的深度解析
在一些SEO材料中,“预处理”通常被简称为“索引”,因为索引是预处理的核心内容之一。搜索引擎蜘蛛抓取的原始页面并不能直接用于查询排名处理。由于搜索引擎数据库中的页面数目巨大,用户输入搜索词后,即使排名程序实时对这么多页面进行相关性分析,计算量也巨大,无法在短时间内返回排名结果。因此,抓取来的页面必须经过预处理,为最终的查询排名做好准备。
与爬行抓取类似,预处理也是在后台提前完成的,用户在搜索时感觉不到这个过程。这一阶段的关键任务是对抓取的数据进行处理,使其变得更加适用于后续的排名计算,提高搜索引擎的效率和响应速度。
一、文字内容提取
当今搜索引擎仍然以文字内容为基础。蜘蛛抓取到的页面HTML代码除了包含用户在浏览器上可见的文字外,还包括大量的HTML格式标签、JavaScript程序等无法用于排名的内容。在搜索引擎的预处理阶段,首要任务是从HTML文件中去除标签和程序,提取出可用于排名的页面文字内容。
例如,对于以下HTML代码:
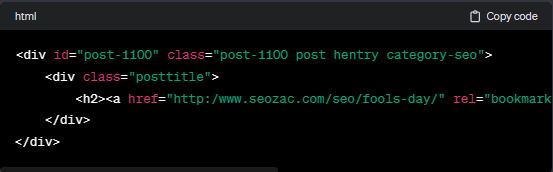
去除HTML代码后,剩下的用于排名的文字只有这一行:

除了可见文字,搜索引擎还会提取出一些包含文字信息的特殊代码,例如Meta标签中的文字、图片替代文字、Flash文件的替代文字以及链接锚文字等。这些提取出的文字信息在后续的排名计算中起着关键的作用。
二、中文分词技术
中文分词是中文搜索引擎独有的关键步骤,作为存储和处理页面内容以及用户查询的基础。不同于英文等语言,中文词汇之间没有天然的空格分隔,因此搜索引擎索引程序必须首先确定哪些字组成一个词,哪些字本身就构成一个词。举例而言,对于“减肥方法”,中文分词会将其划分为“减肥”和“方法”两个词。
中文分词方法主要有两种:基于词典匹配和基于统计。
1. 基于词典匹配:
正向匹配和逆向匹配是两种常见的扫描方向。
根据匹配长度优先级,可分为最大匹配和最小匹配。
方法简单,准确度取决于词典完整性和更新情况。
2. 基于统计:
通过分析大量文字样本,计算字与字相邻出现的统计概率。
出现次数越多的字相邻,形成一个单词的可能性越大。
对新出现的词反应更迅速,有利于消除歧义。
实际应用中,中文分词系统通常混合使用这两种方法,以兼顾速度和准确性。搜索引擎对页面的分词取决于词库的规模、准确性和分词效果,而非页面本身的内容。因此,对于SEO人员而言,分词的操作空间相对较小。唯一可以做的是通过在页面上的某种形式提示搜索引擎,明确某几个字应该被视为一个词处理,特别是在可能产生歧义的情况下。例如,在页面标题、h1标签或黑体中出现关键词时,可以采用特殊标记,使搜索引擎能够更准确地识别和分析。
三、停用词过滤
在英文和中文页面内容中,常常包含一些高频但对内容影响较小的词语,比如中文中的“的”、“地”、“得”等助词,以及“啊”、“哈”、“呀”等感叹词,“从而”、“以”、“却”等副词或介词。这些被称为停用词,因为它们并不在页面的主旨意义上产生重要影响。在英文中,一些常见的停用词包括the, a, an, to, of等。
为了使索引数据更突出页面主题并降低计算量,搜索引擎在索引页面之前会移除这些停用词。这一过程有助于提高搜索引擎的效率,确保检索结果更加精准。停用词过滤是搜索引擎预处理的一个重要步骤,旨在优化检索过程,使用户获取更符合其需求的搜索结果。
四、噪声过滤
许多页面上存在一些与页面主题无关的内容,如版权声明文字、导航条和广告等。以博客导航为例,几乎每个博客页面都包含文章分类、历史存档等导航内容,但这些内容与“分类”、“历史”等关键词实际上并无直接关系。因此,当用户搜索与这些关键词相关的内容时,仅因为页面上包含这些词而返回博客帖子是毫无意义的,也是不相关的。这些内容被认为是噪声,因为它们对页面主题没有实质贡献,反而可能分散用户的注意力。
搜索引擎的任务之一是识别并消除这些噪声,以便在排名时不使用这些与主题不相关的内容。噪声消除的基本方法是根据HTML标签对页面进行分块,明确页面中的页头、导航、正文、页脚、广告等区域。在网站上大量重复出现的区块通常被认定为噪声。通过对页面进行噪声消除,搜索引擎能够更准确地提取和索引页面的主体内容,从而为用户提供更相关和有用的搜索结果。
五、去重处理
搜索引擎在处理页面时需要进行去重处理,因为同一篇文章可能会在不同网站或同一网站的不同网址上重复出现。搜索引擎不倾向于展示重复性的内容,因为这会降低用户的搜索体验。用户在前几页中看到来自不同网站的相同文章可能会感到不满,尽管这些内容都与其搜索相关。因此,在进行索引之前,搜索引擎需要识别和删除重复的内容,这个过程通常被称为“去重”。
去重的基本方法是通过计算页面特征关键词的指纹来实现。指纹是对关键词的数字化表示,通常选择页面主体内容中最具代表性的关键词。这些关键词的选取在分词、去停用词和消噪之后进行。实验证明,通常选择10个特征关键词就足以实现较高的去重准确性,增加关键词数量对去重准确性的提升贡献较小。
常用的指纹计算方法包括MD5算法(信息摘要算法第五版)。这类指纹算法的特点是,对输入(特征关键词及其顺序)进行微小变化就会导致计算出的指纹有很大差距。
了解搜索引擎的去重算法后,SEO人员应明白简单的“的”、“地”、“得”插入或调换段落顺序等伪原创方法并不能躲过搜索引擎的去重处理。因为这些操作无法改变文章的特征关键词,也就无法改变指纹。搜索引擎的去重算法很可能不仅局限于页面级别,而且可能在段落级别进行,因此即使进行混合操作或调换段落顺序,也难以避免搜索引擎对重复内容的准确判别。
六、构建正向索引
正向索引,又称为索引,在经过文字提取、分词、消噪、去重等处理后,搜索引擎获得了具有独特性、能够反映页面主体内容的以词为单位的字符串。随后,搜索引擎索引程序会提取关键词,按照分词程序划分的词语,将页面转换为一个由关键词组成的集合,同时记录每个关键词在页面中的出现频率、出现次数、格式(如出现在标题标签、黑体、H标签、锚文字等)、位置等信息。这样,每个页面都可被记录为一个关键词集合,其中每个关键词的词频、格式、位置等权重信息也都被记录。
搜索引擎索引程序将页面及其关键词形成词表结构,并存储到索引库中。简化的索引词表形式如下所示:

每个文件都对应一个文件ID,文件内容被表示为一个关键词的集合。实际上,在搜索引擎索引库中,关键词也被转换为关键词ID。这种数据结构即为正向索引。
七、构建倒排索引
正向索引虽然能存储页面与关键词的映射关系,但无法满足实时排名的需求。假设用户搜索关键词2,若仅有正向索引,排名程序需要扫描所有索引库中的文件,找到包含关键词2的文件,再进行相关性计算。这样的计算量无法满足实时返回排名结果的要求。
因此,搜索引擎会将正向索引数据库重新构造为倒排索引,将文件到关键词的映射转换为关键词到文件的映射,如下表所示:

在倒排索引中,关键词是主键,每个关键词对应一系列文件,这些文件中都包含了该关键词。当用户搜索某个关键词时,排序程序通过倒排索引可迅速定位到该关键词,并找出所有包含此关键词的文件。
八、链接关系分析
链接关系分析在搜索引擎的预处理中扮演着关键的角色。目前,主流搜索引擎的排名算法中都充分考虑了网页之间的链接关系。在抓取页面内容后,搜索引擎需要提前计算页面上的链接情况,包括指向其他页面的链接、每个页面的导入链接以及使用的锚文本。这些复杂的链接关系形成了网站和页面的链接权重。
Google的PageRank(PR)值是其中最主要的一种链接关系的体现。其他搜索引擎也实施了类似的计算,尽管它们可能不使用"PageRank"这个术语来描述。由于页面和链接的数量庞大,网上的链接关系经常处于更新状态,因此链接关系和PR的计算需要耗费相当长的时间。
关于PR值和链接分析,后续会有专门的文章进行详细介绍。
九、多样文件类型的处理
除了HTML文件之外,搜索引擎通常能够抓取和索引多种以文字为基础的文件类型,包括PDF、Word、WPS、XLS、PPT、TXT等。在搜索结果中,我们经常能看到这些不同类型的文件。但是,目前的搜索引擎还无法有效处理图片和视频,对于Flash等非文字内容,以及脚本和程序,搜索引擎只能进行有限的处理。
尽管搜索引擎在识别图片、从Flash中提取文字内容方面取得了一些进展,但直接通过阅读图片、视频、Flash内容返回结果的目标仍然遥不可及。对于图片和视频内容的排名往往仍然依赖于相关的文字内容,具体情况可以参考后面关于整合搜索的部分。
十、质量评估
在预处理阶段,搜索引擎会对页面内容的质量以及链接的质量等进行评估。过去几年中,百度的绿萝和石榴算法,以及Google的熊猫和企鹅算法等都是预先计算并上线的,而不是在查询时实时计算的。