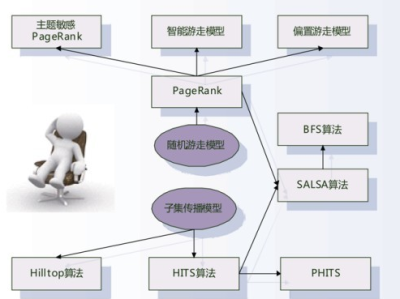
引言
搜索引擎的运作过程错综复杂,接下来的三篇文章将简要介绍搜索引擎如何实现网页排名。尽管以下内容只是涉及搜索引擎技术的表层,但对于大多数SEO从业人员而言已经足够使用。
搜索引擎的工作过程主要可分为三个阶段:
(1)爬虫与数据采集:搜索引擎蜘蛛通过追踪、发现和访问网页,读取页面HTML代码,并将其存入数据库。
(2)预处理:索引程序对采集到的页面数据进行文字提取、中文分词、索引、倒排索引等处理,以备排名程序调用。
(3)排名:用户输入查询词后,排名程序调用索引库数据,计算相关性,然后按一定格式生成搜索结果页面。
爬虫与数据采集是搜索引擎工作的首要步骤,完成了数据收集任务。
一、网络蜘蛛
搜索引擎用于爬行和访问页面的程序被称为蜘蛛(spider)或机器人(bot)。
搜索引擎蜘蛛在访问网站页面时模拟普通用户使用的浏览器。蜘蛛程序发送页面访问请求后,服务器返回HTML代码,蜘蛛程序将收到的代码存入原始页面数据库。为了提高爬行和抓取速度,搜索引擎通常使用多个蜘蛛并发分布爬行。
在访问任何网站时,蜘蛛首先访问网站根目录下的robots.txt文件。如果robots.txt文件禁止搜索引擎抓取某些文件或目录,蜘蛛将遵循协议,不抓取被禁止的网址。
与浏览器类似,搜索引擎蜘蛛也具有标识身份的用户代理名称。网站管理员可以在日志文件中查看搜索引擎的特定用户代理,从而识别搜索引擎蜘蛛。以下是一些常见的搜索引擎蜘蛛名称:
Baiduspider (www.baidu.com)
Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; Firefox/1.5.0.11; 360Spider)
Mozilla/5.0 (compatible; Yaboo! Slurp/3.0; Yahoo! Slurp)
Mozilla/5.0 (compatible; Googlebot/2.1; Googlebot)
Mozilla/5.0 (iPhone; CPU iPhone OS 6_0 like Mac OS X) AppleWebKit/536.26 (KHTML, like Gecko) Version/6.0 Mobile/10A5376 Safari/8536,25 (compatible; Googlebot/2.1; Googlebot)
Mozilla/5.0 (compatible; bingbot/2.0; Bingbot)
Sogou web robot (www.sogou.com)
Sosospider (help.soso.com)
Mozilla/5.0 (compatible; YodaoBot/1.0; YodaoBot)
二、链接跟踪与爬行策略
为了尽可能抓取更多页面,搜索引擎蜘蛛通过追踪页面上的链接,沿着链接从一个页面爬到另一个页面,仿佛蜘蛛在蜘蛛网上行进一样,这也解释了搜索引擎蜘蛛名称的由来。
整个互联网由相互链接的网站和页面组成。理论上,蜘蛛可以从任何一个页面出发,顺着链接爬行到互联网上的所有页面。然而,由于网站和页面的链接结构异常复杂,蜘蛛需要采取特定的爬行策略才能有效遍历所有页面。
最简单的爬行遍历策略分为两种:深度优先和广度优先。
1. 深度优先策略
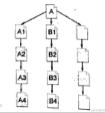
深度优先策略是指蜘蛛沿着发现的链接一直向前爬行,直到无法再向前为止。然后返回到第一个页面,沿着另一个链接再一直向前爬行。以图2-1为例,蜘蛛跟踪链接从A页面爬行到A1、A2、A3、A4,到达A4页面后,由于没有其他链接可跟踪,蜘蛛返回A页面,再顺着另一个链接爬行到B1、B2、B3、B4。在深度优先策略中,蜘蛛一直爬到无法再向前为止,才返回爬另一条线。
2. 广度优先策略
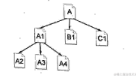
广度优先策略是指蜘蛛在一个页面上发现多个链接时,不是顺着一个链接一直向前,而是把页面上所有第一层链接都爬一遍,然后再沿着第二层页面上发现的链接爬向第三层页面。如图2-2所示,蜘蛛从A页面顺着链接爬行到A1、B1、C1页面,直到A页面上所有链接都爬完。
从理论上说,无论是深度优先还是广度优先,只要蜘蛛有足够的时间,都能爬完整个互联网。然而,在实际工作中,蜘蛛的带宽资源和时间都是有限的,不可能爬完所有页面。实际上,即使是最大的搜索引擎也只是爬行和收录了互联网的一小部分。
深度优先和广度优先通常是混合使用的,以照顾尽量多的网站(广度优先),也能照顾到一部分网站的内页(深度优先)。同时,考虑到页面权重、网站规模、外链、更新等因素,蜘蛛会根据具体情况进行策略调整。
三、引诱搜索引擎蜘蛛
尽管理论上搜索引擎蜘蛛有能力爬行和抓取所有页面,实际上却不能且不会这样做。对于SEO从业人员来说,为了让更多页面被搜索引擎蜘蛛收录,就需要采取措施来吸引蜘蛛进行抓取。由于不能抓取所有页面,蜘蛛的目标是尽量抓取重要页面。以下是影响页面重要性的几个因素:
1. 网站和页面权重
网站质量高且资历老的被认为具有较高权重,蜘蛛会深度爬行这类网站上的页面,因此更多内页会被收录。
2. 页面更新频率
蜘蛛在每次爬行时都会存储页面数据。如果两次爬行发现页面内容与之前完全相同,说明页面没有更新。频繁更新的页面会更吸引蜘蛛,蜘蛛也会更加频繁地访问这类页面,同时更快地跟踪和抓取新页面。
3. 导入链接
无论是外部链接还是同一网站内的链接,页面要被蜘蛛抓取,就必须有导入链接进入页面,否则蜘蛛无法知道页面的存在。高质量的导入链接通常会增加页面的爬行深度。
4. 与首页的点击距离
一般来说,网站首页具有最高权重,大多数外部链接指向首页,因此蜘蛛频繁访问首页。距离首页点击越近,页面权重越高,也就更容易被蜘蛛爬行。
5. URL结构
页面权重是在收录并进行选代计算后得知的,因此蜘蛛在抓取前需要进行预判。除了考虑链接、与首页距离、历史数据等因素外,短且层次浅的URL也可能被直观认为在网站上具有较高权重。
综合考虑这些因素,SEO从业人员可以采取相应措施来优化页面,提高被搜索引擎蜘蛛抓取的机会。
四、URL地址管理
为了防止重复的爬行和抓取工作,搜索引擎建立了一个地址库,用于记录已经发现但尚未抓取的页面以及已经抓取的页面。蜘蛛在发现链接时并不会立即访问,而是将URL存入地址库,然后按计划进行抓取。
地址库中的URL主要来源于以下几个渠道:
人工录入的种子网站: 这些网站由人工指定,作为搜索引擎开始爬行的起点。
蜘蛛抓取页面解析得到的新链接: 通过解析HTML,蜘蛛从页面中提取新的链接URL,并与地址库中的数据进行对比。如果是地址库中没有的网址,就会存入待访问地址库。
站长通过搜索引擎网页提交表格提交的网址: 站长可以通过表格将网址提交给搜索引擎,这些提交的网址会被存入地址库。
站长通过XML网站地图、站长平台提交的网址: 站长还可以通过提供XML网站地图或站长平台提交网址,这些也会被加入地址库。
蜘蛛按照页面的重要性从待访问地址库中提取URL,进行访问和页面抓取。随后,该URL会从待访问地址库中删除,并加入已访问地址库。
尽管大多数主流搜索引擎提供了站长提交网址的表格,但这些提交的网址只是暂时存入地址库,并不能保证被收录。搜索引擎更倾向于通过蜘蛛自行跟踪链接来发现新页面。因此,站长的页面提交对搜索引擎收录的影响微乎其微。搜索引擎更喜欢通过自身跟踪链接的方式发现新的页面。
五、数据存储与文件编号
搜索引擎蜘蛛将抓取的数据存入原始页面数据库,这些页面数据与用户浏览器获取的HTML完全一致。每个URL都被分配一个独特的文件编号,以便在数据库中进行标识和管理。
六、爬行中的复制内容检测
通常,检测和删除复制内容是在预处理过程中进行的,但现代蜘蛛在爬行和抓取文件时也会执行一定程度的复制内容检测。当蜘蛛在权重较低的网站上发现大量转载或抄袭内容时,很可能会中止继续爬行的操作。这就解释了为什么有些站长在日志文件中看到了蜘蛛,但页面却从未真正被收录的原因之一。
在爬行时进行复制内容检测有助于搜索引擎提高搜索结果的质量,避免展示重复或低质量的信息。这也促使站长注意维护原创内容,提升网站在搜索引擎中的可信度和权重。