前言
在Google问世之前,传统搜索引擎主要依赖页面内容中的关键词匹配用户查询词以进行排名。然而,这种排名方式的弊端显而易见,容易被人为操纵。黑帽SEO通过在页面上堆积关键词或添加与主题无关的热门关键词,能够提高排名,导致搜索引擎排名结果的质量下降。现代搜索引擎普遍采用链接分析技术,以减少垃圾信息,提升用户体验。本节将简要探讨链接在搜索引擎排名中的应用原理。
将链接因素纳入排名考量,有助于减少垃圾信息,提高搜索结果的相关性,同时也让传统关键词匹配无法排名的文件得以处理。例如,图片和视频文件无法通过关键词匹配进行排名,但通过外部链接,搜索引擎可以获取这些文件的内容信息从而进行排名。
这一方法也使得不同语言的页面能够被排名。在百度或google.cn搜索“SEO”,我们可以看到英文以及其他语言的SEO网站。甚至在搜索“搜索引擎优化”时,也能看到非中文页面,这是因为某些链接使用“搜索引擎优化”作为锚文本指向英文页面。
当前,链接因素的重要性已经超越了页面内容。然而,理解链接关系相对较为抽象,而页面上的因素对排名的影响是可见的,更容易直观理解。以一个简单的例子来说明,当搜索特定关键词时,SEO专业人员通过观察前几页的结果,能够了解关键词出现在标题标签中的影响,以及在最前面出现的影响。对于有技术资源的人来说,还可以进行大规模的统计分析,计算关键词在标题标签中不同位置与排名之间的关系。尽管这种关系未必是因果关系,但至少是统计上的相关性,帮助SEO人员初步了解如何进行优化。
相较而言,链接对排名的影响难以直观了解,也难以进行统计分析,因为没有人能够获得搜索引擎的链接数据库。我们所能做的最多只是定性观察和分析。
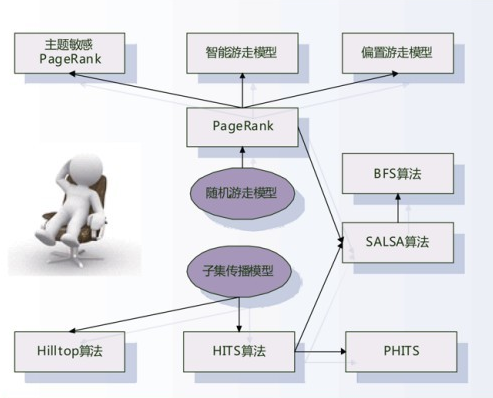
接下来将介绍一些关于链接的专利,这些专利多少透露了链接在搜索引擎排名中的使用方法和地位。"
一、李彦宏的链接分析专利
李彦宏,百度创始人,早在回国创建百度之前,是美国顶级的搜索引擎工程师之一。据传闻,在寻找风险投资时,投资人询问其他三个搜索引擎领域的技术专家一个问题:要了解搜索引擎技术,应该问谁?这三位专家中有两位回答说:搜索引擎的事情就问李彦宏。由此可见,投资人断定李彦宏是最了解搜索引擎技术的人之一。
在现实生活中,链接关系的应用类似于判断哪个页面(人)最具权威性。不能仅仅看页面(人)自己怎么说,还需要考虑其他页面(人)对其的评价。
早在1997年,李彦宏就提交了一份名为“超链文件检索系统和方法”的专利申请,展示了对链接分析的前瞻性研究,比Google创始人发明PageRank要早得多。在这份专利中,李彦宏提出了一种基于链接的排名方法,与传统信息检索系统有所不同。
这个系统不仅索引页面,还建立了一个链接词库,记录链接锚文字的相关信息,如锚文字中包含的关键词、发出链接的页面索引、包含特定锚文字的链接总数以及包含特定关键词的链接指向哪些页面。词库不仅包含关键词原型,还包括同一个词干的其他衍生关键词。
基于这些链接数据,特别是锚文字,计算出基于链接的文件相关性。在用户进行搜索时,将基于链接的相关性与传统关键词匹配的相关性综合使用,以获得更准确的排名。
尽管如今这种基于链接的相关性计算已经成为搜索引擎算法的一部分,为每位SEO从业者所熟知,但在十七八年前,这无疑是一个极具创新性的概念。当然,现代搜索引擎算法对链接的考虑已经不仅仅局限于锚文字,变得更加复杂。
这份专利的所有者是李彦宏当时所在的公司,而发明人则是李彦宏本人。有兴趣的读者可以在美国专利局发布的“超链文件检索系统和方法”专利详情页面查看详细信息。
二、HITS算法解析
HITS(Hyperlink-Induced Topic Search)算法是一种由Jon Kleinberg于1997年提出的链接分析算法,该算法已被专利化(专利详情可在美国专利局查询)。HITS算法通过计算两种值,即枢纽值(Hub Scores)和权威值(Authority Scores),对用户输入的查询词返回的匹配页面进行评估。这两个值是相互依存、相互影响的。
在HITS算法中,枢纽值表示页面上所有导出链接指向页面的权威值之和,而权威值表示所有导入链接所在页面的枢纽值之和。简而言之,HITS算法识别并提取了两类重要的页面,即枢纽页面和权威页面。枢纽页面可能自身没有很多导入链接,但却有很多导出链接指向权威页面。权威页面可能导出链接不多,但有很多来自枢纽页面的导入链接。
典型的枢纽页面包括雅虎目录、开放目录或好123等网站目录,它们通过指向其他权威网站而发挥着枢纽的作用。权威页面通常具有很多导入链接,其中包含很多来自枢纽页面的链接,因为权威页面提供真正相关内容。
HITS算法是为特定查询词设计的,因此被称为主题搜索。然而,HITS算法的主要缺点在于其在查询阶段执行计算,而不是在抓取或预处理阶段进行。这使得HITS算法在搜索引擎中的应用相对较少,因为它在查询排名响应时间上牺牲了一些性能。尽管如此,HITS算法的思想可能会在搜索引擎的索引阶段得到融入,即通过链接关系找出具有枢纽或权威特征的页面。
成为权威页面是首要目标,尽管这相对较为困难,唯一的方法就是获取高质量的链接。当你的网站无法成为权威页面时,可以考虑将其定位为枢纽页面。因此,导出链接也成为当前搜索引擎排名的因素之一。坚持不链接到其他网站的做法并非良好的SEO方法。
三、TrustRank算法解析
TrustRank是一种基于链接关系的排名算法,在近年来备受关注。TrustRank可译为“信任指数”。
该算法最初源自2004年由斯坦福大学和雅虎共同研发,旨在检测垃圾网站,并于2006年申请了专利。算法的发明者还发布了一份专门解释TrustRank算法应用的PDF文件,可在以下网址下载:https://www.vldb.org/conf/2004/RS15P3.PDF
值得注意的是,TrustRank算法并非由Google提出,尽管Google在搜索引擎市场份额最大,并且TrustRank在Google排名中也扮演着重要角色,但有些人误以为TrustRank是由Google提出的。更加混淆的是,Google曾申请TrustRank商标,但该商标中的TrustRank指的是Google检测含有恶意代码网站的方法,而非排名算法中的信任指数。
TrustRank算法的基本假设是:好的网站很少会链接到坏的网站,而反之则不一定成立。也就是说,坏的网站很少链接到好的网站。相反,垃圾网站常常试图通过链接到高权威、高信任指数的网站来提高自身的信任指数。
基于这一假设,TrustRank算法试图挑选出可以百分之百信任的网站,这些网站的TrustRank被评定为最高。这些TrustRank最高的网站链接到的网站虽然信任指数略有下降,但仍然较高。随着链接层次的增加,信任度逐渐下降。虽然好的网站有时会链接到一些垃圾网站,但距离第一层网站点击越近的网站,传递的信任指数越高,距离越远则依次下降。通过TrustRank算法,可以为所有网站计算出相应的信任指数,距离第一层网站越远,成为垃圾网站的可能性就越大。
计算TrustRank值的首要步骤是选择一批种子网站,然后进行人工查看并设定初始的TrustRank值。有两种常见的挑选种子网站的方法,一种是选择导出链接最多的网站,因为TrustRank算法考虑指数随导出链接的减少而衰减。在某种程度上,导出链接较多的网站可视为“逆向PR值”较高。另一种选择种子网站的方法是选取PR值较高的网站,因为PR值越高,该网站在搜索结果中出现的概率越大。这些网站正是TrustRank算法最关注的,需要调整排名的网站。对于PR值较低的页面,在没有TrustRank算法的情况下,其排名就已经相对较低,计算TrustRank的意义较小。
根据估算,挑选大约两百个左右的网站作为种子,就能相对精确地计算出所有网站的TrustRank值。
计算TrustRank随着链接关系减少的公式有两种方式。一种是按照链接次数进行衰减,即第一层页面的TrustRank指数是100,第二层页面衰减为90,第三层衰减为80。另一种计算方法是按照导出链接数目分配TrustRank值,也就是说,如果一个页面的TrustRank值是100,页面上有5个导出链接,每个链接将传递20%的TrustRank值。这两种计算方法通常会综合使用,整体效果都是随着链接层次的增加,TrustRank值逐步降低。
得出网站和页面的TrustRank值后,可以通过两种方式影响排名。一种是将传统排名算法挑选出的相关页面,根据TrustRank值进行重新排名调整。另一种是设定一个最低的TrustRank值门槛,只有超过这个门槛的页面才被认为有足够的质量进入排名,低于门槛的页面将被过滤出搜索结果之外。
尽管TrustRank算法最初是作为垃圾检测的方法,但在现代搜索引擎排名算法中,TrustRank概念的应用更为广泛,常常对大多数网站的整体排名产生影响。TrustRank算法最初关注页面级别,但现在在搜索引擎算法中,TrustRank值通常在域名级别表现,域名的信任指数越高,整体排名能力越强。
四、Google PR
PR是指PageRank,是Google创始人之一拉里·佩奇发明的一种用于表示页面重要性的概念,也是所有基于链接的搜索引擎理论中最为著名的之一。在SEO领域,即便人们对其他链接理论不太了解,对PR的概念也是司空见惯。
Google PR的核心思想类似于科技文献中的互相引用概念,即被其他文献引用较多的文献,很可能是比较重要的文献。同样地,页面反向链接越多,该页面的PR值就越高,因而被认为更为重要。
PR值的计算复杂且涉及算法细节,但它在搜索引擎排名中的应用广泛,是衡量页面重要性的一项关键指标。因此,Google PR成为了SEO领域中一个不可忽视的概念。
1. PR的概念和计算
互联网可视为由结点和链接构成的有向图,其中每个页面是一个结点,页面之间的有向链接传递着页面的重要性。链接传递的PR值取决于链接源页面的PR值,发出链接的页面PR值越高,传递出去的PR也越高。传递的PR值还与页面上的导出链接数目有关。对于给定PR值的页面,如果能传递到下级页面100份PR,且页面上有10个导出链接,每个链接传递10份PR;而如果页面上有20个导出链接,每个链接只能传递5份PR。因此,一个页面的PR值受导入链接总数、链接源页面的PR值以及链接源页面上的导出链接数目的影响。
PR值的计算公式如下:
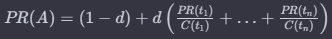
在公式中,A代表页面A,
PR(A) 是页面A的PR值,d是阻尼指数(通常取0.85),t 1 …t n 代表链接向页面A的页面。C代表页面上的导出链接数目,C(t 1 ) 表示页面t 1 上的导出链接数目。
PR值的计算需要经过多次迭代,因为页面A的PR值取决于链接向A的页面t 1 到t n 页面的PR值,而t 1 到t n 页面的PR值又取决于其他页面的PR值,可能还包含页面A。通过设定初始值,进行多次迭代计算,各个页面的PR值将逐渐趋于稳定,最终收敛到一个特定值。研究证明,无论初始值如何选择,迭代计算的最终PR值不受影响。
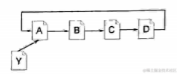
阻尼系数的引入是为了防止循环中PR值无限增长。在一个循环中,如果没有阻尼系数,循环中的页面PR将趋于无穷大。通过引入阻尼系数,PR在传递时自然衰减,确保PR计算最终能稳定在一个值上。
2. PR的两个比喻模型
有关PR,存在两个著名的比喻模型。其中一个比喻是“投票”。在这个模型中,链接就类似于民主投票,当A页面链接到B页面时,相当于A页面对B页面进行了一次投票,提升了B页面的重要性。同时,A页面的PR值决定了其所能投出去的投票力,因此,PR值越高的页面,其投票也更为重要。从这个角度看,传统基于关键词匹配的算法主要关注页面自身对内容的表述,而基于链接的PR则更注重其他人对页面的评价。
另一个比喻是“随机冲浪”。设想一个访问者从一个页面开始,不断地随机点击链接,持续访问下一个页面。当用户感到无聊不再点击链接时,随机跳转到另一个网址,再次开始持续点击。在这个模型中,PR值表示一个页面在这种随机冲浪访问中被访问到的概率。导入链接越多的页面,被访问到的概率越高,因此其PR值也越高。阻尼系数与随机冲浪模型相关,(1−d)=0.15 实际上表示用户感到无聊,停止点击,随机跳到新URL的概率。通过这两个比喻模型,我们能更好地理解链接对页面重要性的影响。
3. 工具条PR
我们无法直接获取真实用于排名计算的Google PR值,而我们通常看到的是Google工具条上的PR值。然而,需要注意的是,工具条PR值并不能准确反映真实PR值。真实的PR值是一个准确的数字,大于0.15,并且没有上限,而工具条上显示的PR值已经被规范化为0到10的11个整数范围。换句话说,工具条上最小的近似PR值是0,最大的近似PR值是10。实际上,每个工具条PR值代表的是一个相当大的范围,工具条PR值相同的页面的真实PR值可能相差很多倍。
真实的PR值是在不间断计算和更新中的,而工具条PR值只是某个特定时间点上真实PR值的简化快照。在过去的十多年中,Google可能会每个月快速更新一次工具条PR,或者可能在近一年内进行一次更新。然而,在2014年10月,Google的John Mueller员工在一次视频问答中表示,Google以后可能不再更新工具条PR。最后一次工具条PR更新是在2013年12月6日,而且那次更新是Google工程师在进行其他任务时无意中进行的,不是按计划进行的。因此,基本上可以确定,Google将不再更新工具条PR值。近几年工具条PR值更新的日期如下表所示。
工具条PR与反向链接数目之间呈对数关系,而非线性关系。换句话说,从PR1到PR2所需的外部链接数量是100个,而从PR2到PR3则需要大约1000个,而PR5到PR6所需的外部链接数量更多。因此,PR值越高的网站想要提升一个级别所需的时间和努力相比于PR值较低的网站更为显著。
4. 关于PR的几个误解
PR的英文全称是PageRank,这个名字来源于发明人佩奇(Page)的姓氏,而巧合的是Page在英文中也是页面的意思。因此,严格来说,PageRank这个名字应该被翻译为佩奇级别,而不是页面级别。然而,由于惯例和一语双关的幽默,人们普遍称之为页面级别。
PR值与链接之间存在关联,但并不仅仅与链接相关。经常有站长询问,他的网站存在很长时间,内容也都是原创的,为什么PR值仍然是零呢?实际上,PR与站长的认真程度、站点的存在时间以及内容的原创性并没有直接关系。PR值的存在取决于反向链接的数量,有反向链接就有PR,没有反向链接就没有PR。一个高质量的原创网站通常能够自然地吸引到更多的外部链接,从而间接提高PR值,但这并非绝对必然的。
工具条PR值的更新与页面排名的变化在时间上没有直接的对应关系。在工具条PR值更新的过程中,经常有站长说PR值提高了,网站的排名也随之提高。然而,这种关联只是时间上的巧合。前面已经提到,真实用于排名计算的PR值是持续不断地计算和更新的,随时纳入排名算法。而我们看到的工具条PR值只是每几个月更新一次,而且最后一次更新已经是在2013年12月。
即使在工具条PR值还在更新时,当我们观察到PR值的变化时,真实的PR值早在几个月之前就已经被计算并纳入排名算法。因此,通过研究工具条PR值的变化来探讨PR值与排名变化之间的关系是毫无意义的。
5. PR的意义
Google的工程师多次强调,Google PR现在已经是一个被过度宣传的概念。实际上,PR只是Google排名算法中的众多因素之一,其重要性已经大幅降低,因此SEO从业人员无需过于执着于提高PR值。这也可能是Google不再更新工具条PR值的原因之一。
当然,尽管PR的重要性降低,它仍然是Google排名算法中的一个关键因素。除了对排名的直接影响外,PR的重要性还体现在以下几个方面:
(1) 网站收录深度和总页面数: 由于搜索引擎蜘蛛爬行时间和数据库空间都是有限的,PR值越高的网站更有可能被收录更多页面,蜘蛛也会更深入地爬行内页。对于大中型网站,首页的PR值是影响网站收录的关键因素之一。
(2) 访问及更新频率: PR值较高的网站往往会得到更频繁的搜索引擎蜘蛛访问,从而能够更快速地收录新页面或更新现有页面的内容。由于新页面通常会在现有页面上设置链接,高访问频率也意味着更快地发现新页面。
(3) 重复内容判定: 当Google在不同网站上发现完全相同的内容时,它会选择一个版本作为原创,将其他版本视为转载或抄袭。在判断哪个版本为原创时,PR值是一个重要的考虑因素。这也解释了为什么那些权重高、PR值高的大型网站的内容经常被视为原创,而转载到小网站的内容可能被视为非原创。
(4)排名初始子集的选择: 在排名的初始阶段,搜索引擎无法对所有文件进行相关性计算,因此需要从中选择一个初始子集进行进一步计算。这个选择主要基于页面的重要性而非关键词相关性,而PR值正是衡量页面重要度的一个指标。
当前的PR算法相较于最初由拉里·佩奇在专利中描述的算法,肯定经历了改进和变化。一个可观察的现象是,PR算法可能已经排除了一些Google认为可疑或无效的链接,比如付费链接、博客和论坛中的垃圾链接等。因此,有时我们会发现一个页面具有PR6或PR7的导入链接,但经过几次工具条PR的更新后,其PR值却仍然保持在PR3或PR2。按理说,一个PR6或PR7的链接应该能够将被链接的页面带到PR5或PR4。因此,很可能Google已经将一些其认为可疑的链接排除在PR计算之外。
另一个例子是关于同一页面上不同位置的链接是否应该传递相同数量的PR值。例如,正文、侧栏导航和页脚的链接是否应该同等对待?最初的PR设计并未考虑链接位置的因素,但显然,不同位置的链接具有不同的重要性,被真实用户点击的概率也是不同的。因此,是否已经在现有的Google PR算法中引入了对这些差异的矫正呢?
PR算法的专利发明人是拉里·佩奇,专利的所有权归属斯坦福大学,而Google公司则拥有该算法的永久使用权。尽管PR是Google拥有专利使用权的算法,但其他主流搜索引擎也都采用类似的算法,尽管名称不同。因此,这里提到的PR的作用和意义同样适用于其他搜索引擎。
五、Hilltop算法
Hilltop算法是由Krishna Baharat在约2000年研究的,他在2001年申请了专利,并将专利授权给了Google,随后Krishna Baharat本人也加入了Google的团队。
Hilltop算法的简单理解可以视为与特定主题相关的PR值。传统的PR值与特定关键词或主题无关,仅计算链接关系。这可能导致一些潜在漏洞。例如,一个关于环保内容的大学页面具有极高的PR值,但该页面链接到一个儿童用品网站,这个链接之所以存在可能仅仅是因为这个大学页面的维护者是一位教授,他的太太在那个卖儿童用品的公司工作。这种与主题无关但却有着极高PR值的链接可能使一些网站获得良好的排名,尽管其权威性和相关性并不高。
Hilltop算法试图纠正这种潜在的问题。它同样关注链接关系,但更注重来自主题相关页面的链接权重。在Hilltop算法中,将这些主题相关页面称为“专家文件”。显然,针对不同的主题或搜索词,存在不同的专家文件。
根据Hilltop算法,用户在Google中进行搜索查询后,首先按照正常排名算法找到一系列相关页面并进行排名。然后,算法计算这些页面中有多少来自专家文件的、与搜索主题相关的链接。页面获得的来自专家文件的链接越多,其排名分值就越高。根据Hilltop算法的初始设想,一个页面至少需要具备两个来自专家文件的链接,否则其Hilltop值将为零。
通过专家文件链接计算得到的分值被称为LocalRank。排名程序根据LocalRank值对传统排名算法计算的排名进行重新调整,最终得出最终排名。这就是前述搜索引擎排名阶段最后的过滤和调整步骤。
在Hilltop算法最初的文献和专利中,对专家文件的选择有一些不同的描述。在初次研究中,Krishna Baharat将专家文件定义为包含特定主题内容且具有较多导出链接指向第三方网站的页面,这与HITS算法中的枢纽页面有些相似。专家文件的链接指向的页面与专家文件本身不应有关联,这种关联包括来自同一主域名下的子域名,以及来自相同或相似IP地址的页面等。通常,最常见的专家文件来自学校、政府和行业组织的网站。
在最初的Hilltop算法中,专家文件是事先挑选好的。搜索引擎可以根据最常见的搜索词预先计算一套专家文件,用户进行搜索时,排名算法从预先计算的专家文件集合中选择与搜索词相关的专家文件子集,然后计算这个子集中的链接的LocalRank值。
然而,在2001年所申请的专利中,Krishna Baharat描述了一种不同的专家文件挑选方法。专家文件并不是事先选定的,而是在用户搜索特定查询词后,搜索引擎按照传统算法挑选出一系列初始相关页面,这些页面即成为专家文件。然后,Hilltop算法再次计算这些页面中哪些网页具有来自于集合中其他页面的链接,并赋予这些链接相对较高的LocalRank值。由于传统算法得到的页面集合已经具备了相关性,这些页面向某一特定页面提供的链接自然具有较高的权重。这种挑选专家文件的方法是实时进行的。
尽管一般认为Hilltop算法对2003年年底的佛罗里达更新产生了重大影响,但是否真正被融入Google排名算法中目前没有确切的证据。Google既未承认也未否认其排名算法中是否使用了某项专利。然而,从排名结果的观察以及Krishna Baharat加入Google等迹象来看,Hilltop算法的思想显然受到了Google的高度关注。
Hilltop算法为SEO提供了一个重要提示,即在建设外部链接时应更加关注主题相关性,尤其是对那些本身排名较好的网站和页面。简便的方法是搜索某个关键词,找到当前排名较高的页面作为最佳的链接来源,甚至可能某个来自竞争对手网站的链接效果更佳。当然,获得这类链接的难度较大。这里所说的排在前面,包括排在前几百位,而不仅仅是一般用户常看到的前二三十名,因为排在前几百名的页面已经可以被视为专家文件。