

随着网络发展,保护网站安全成为至关重要的任务之一。本文将深入讨论如何通过.htaccess文件实现阻止不受欢迎的访客或机器人访问你的网页的方法。
.htaccess是服务器中的一个隐藏文件,它能够控制网页与其他工具之间的访问权限。
以下是几种不同的方法,通过编辑.htaccess文件,我们可以阻止不需要的访客进入你的网页。
▍使用IP地址阻止
有时,网站问题可能是由一组或多组IP地址造成的。在这种情况下,你可以通过简单地编辑代码来阻止这些有问题的IP地址。
阻止单一IP地址
如果你只想阻止一组IP或者多个不同范围内的IP,你可以使用以下代码:

阻止多个IP地址
阻止一个IP范围,例如123.123.123.1 - 123.123.123.255,你也可以删除最后一组数字。

你还可以使用CIDR(无类别区域间路由)标记方式来阻止IP。
阻止范围123.123.123.1 - 123.123.123.255,使用 123.123.123.0/24。
阻止范围123.123.64.1 - 123.123.127.255,使用 123.123.123.0/18。

▍根据User-Agent字符串阻止不良用户
一些恶意用户会使用不同的IP发送请求,但在所有这些请求中,只使用相同的User-Agent。在这种情况下,你可以仅仅阻止用户的User-Agent字符串。
阻止单个不良User-Agent
如果你只想阻止一个特定的User-Agent字符串,你可以使用以下方法:
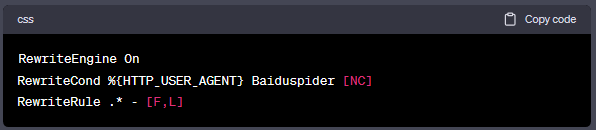
或者你也可以使用BrowserMatchNoCase服务器指令:
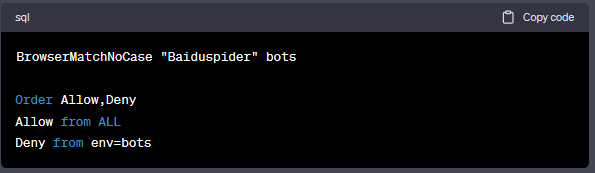
阻止多个不良User-Agent
如果你想一次阻止多个User-Agent,你可以使用以下方法:
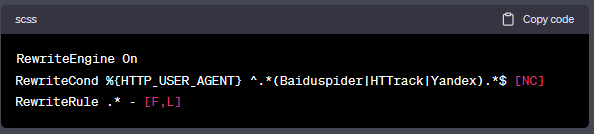
或者你也可以使用BrowserMatchNoCase服务器指令:
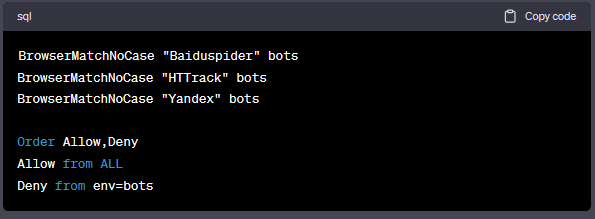
▍阻止不良引荐链接(盗链)
阻止单个不良引荐链接
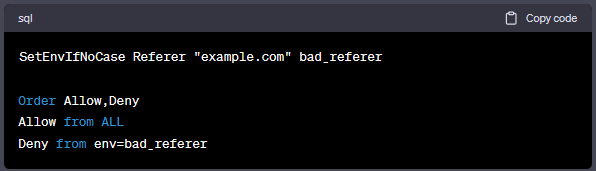
如果你只想阻止一个特定的引荐链接,例如:example.com,你可以使用以下方法:
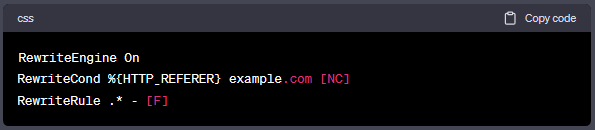
或者你也可以使用SetEnvIfNoCase服务器指令:
阻止多个不良引荐链接
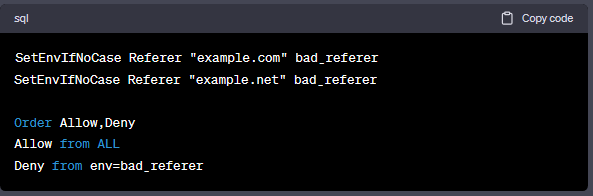
如果你想阻止多个引荐链接,例如:example.com、example.net,你可以使用以下方法:
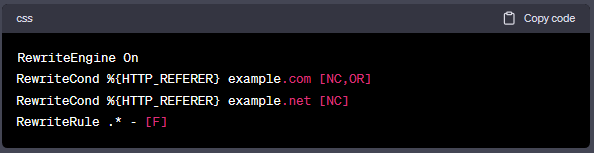
或者你也可以使用SetEnvIfNoCase服务器指令:
▍临时阻止恶意搜索引擎爬虫
在某些情况下,你可能不想直接发送403错误页面给访客,因为那是一个(长时间)拒绝他进入网页的消息。
以下代码将以503响应的方式设置基本的错误页面消息,这是一种默认方式告诉搜索引擎,这个请求只是暂时被阻止,并且一段时间后可以再次尝试。503响应与403响应是不同的,503是通过430响应来暂时拒绝访问权限,像是GOOGLE将会确认为503响应后,他们将会再次尝试检索网页,并非删掉他的检索。
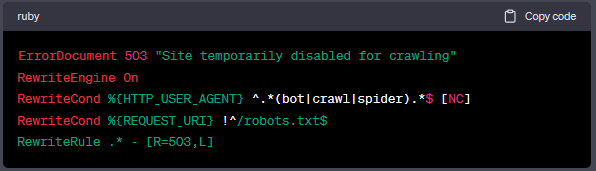
当你注意到一些新的搜索引擎爬虫在频繁抓取你的网页,而你希望阻止他们或让他们减少频繁抓取,你可以使用robots.txt文件来处理,这是一个不错的方法。一样的,它会以503方式回应请求,直到他们读取到你新的robots.txt规则,再来执行它。你可以阅读【合理运用robots.txt文件保护你的网站隐私】。
以上代码会抓取包含搜索引擎、搜索爬虫、搜索蜘蛛在内的任何请求,大多数主要的搜索引擎都是符合的,第二个RewriteCond是允许这些爬虫仍然可以请求robots.txt文件来核对最新的规则,但是任何其他的请求都会得到503网页回应或是"Site temporarily disabled for crawling"。正常来说,你在开始使用两天后,还不想删除503回应的话,GOOGLE可能会开始理解成长时间的服务器中断,并且会开始从GOOGLE的索引中删除你的网页链接。
希望这些方法能够对保护你的网站安全起到一定的帮助。如果你有任何疑问或需要进一步的协助,请随时与我们联系。











