在前端开发领域,SEO问题是一个常见挑战,即搜索引擎难以正确爬取和收录网站,从而导致网站在搜索结果中排名较低。为了应对这个问题,我们可以运用Puppeteer来实现服务端渲染(SSR),将网站的HTML代码提供给搜索引擎爬虫。
Puppeteer是由Google Chrome团队开发的Node.js库,提供了一套高级API,用于控制Chrome或Chromium浏览器的各种操作,实现类似人类对浏览器的操作,如打开网页、输入文字、点击按钮等。通过Puppeteer,我们能够轻松进行自动化测试、爬虫、网页截图等任务。
解决SEO问题通常来说,搜索引擎爬虫会在浏览器中加载网页,然后解析并收录渲染后的HTML代码。对于单页应用(SPA)这类只有在执行JavaScript代码后才能渲染页面的网站,搜索引擎爬虫无法正确解析和收录页面。这时候,使用服务端渲染(SSR)就成为解决之道。
利用Puppeteer,我们能够模拟浏览器行为,将网站在浏览器中渲染,然后将渲染后的HTML代码交给搜索引擎爬虫。这样一来,搜索引擎就能准确解析和收录我们的页面,提升网站在搜索结果中的排名。
实施方式
在本文中,我们选用Koa2作为后端框架,并使用Nginx作为反向代理服务器。通过Nginx,我们能够将请求分为来自搜索引擎和来自普通用户的两类。对于搜索引擎的请求,我们将其导向Node服务,利用Puppeteer将网站渲染后返回HTML代码。而对于普通用户的请求,我们直接将其转发到目标网站。
安装依赖
首先,我们需要安装以下依赖:

后端代码编写
我们将编写一个后端代码的示例,创建一个名为server.js的文件。以下是代码示例:
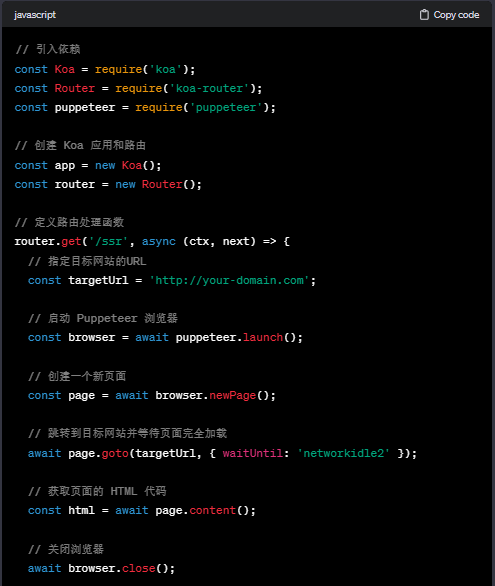
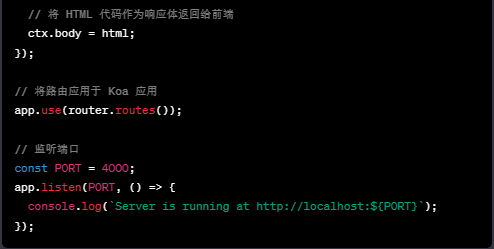
在上述代码中,我们使用 Koa 构建了一个简单的服务器,并通过 koa-router 处理路由。针对 /ssr 路径,我们使用 Puppeteer 打开指定的目标网站,并返回其 HTML 代码。最后,将 HTML 代码作为响应体返回给前端。
后端代码测试
我们已经成功编写了后端代码,现在是时候启动服务并测试它是否能够顺利返回目标网站的HTML代码了。请按照以下步骤在终端中执行相应命令:
打开终端,并执行以下命令启动后端服务:

如果一切顺利,你将会看到返回的目标网站HTML代码。这证明后端代码已经成功运行并能够正常工作。
Nginx配置
现在我们需要配置Nginx,使其能够区分搜索引擎和普通用户,并将请求转发到不同的服务。为了实现这一目标,我们可以利用Nginx的$http_user_agent变量来判断请求的来源。通过检查$http_user_agent中是否包含某些搜索引擎关键字,我们可以确定请求是否来自搜索引擎。以下是在Nginx配置文件中添加相应代码的步骤:
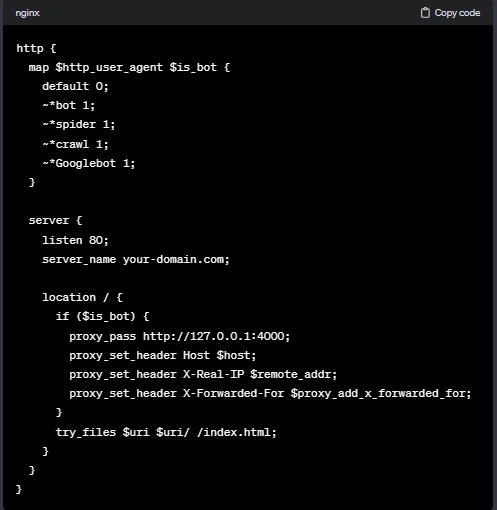
在上述配置文件中,我们使用了Nginx的map模块,将$http_user_agent(即请求头中的User-Agent)映射到是否是搜索引擎的标志$is_bot。在server块中,我们设置了监听端口为80,server_name为你的域名(站点/前端项目)。
对于location /,我们首先进行了$is_bot的判断。如果是搜索引擎,则将请求代理到本地的4000端口(即Node服务的端口),同时通过proxy_set_header指令将一些请求头信息传递给后端服务器。对于普通用户的请求,我们使用try_files指令来查找静态资源。
需要注意的是,在代理请求时,我们通过proxy_set_header指令将一些请求头信息传递给后端服务器,以便后端进行处理。
总的来说,在本文中,我们介绍了如何使用Puppeteer解决前端SEO问题。通过利用Nginx的反向代理能力进行请求分流,结合Puppeteer进行页面渲染,我们最终将渲染后的HTML返回给搜索引擎。这种方案有效解决了前端框架在SEO方面的不足,提升了网站在搜索引擎中的排名。
在实际应用中,我们还需考虑更多问题,如Puppeteer的性能、网站访问量以及反爬虫策略等。