一、探索搜索引擎的技术奥秘
若想深入了解SEO的解决方案及其背后的原理,我们不可避免地需要探究搜索引擎的本质。对于那些对浏览器工作机制不太熟悉的人来说,搜索引擎可能仅仅是个抽象的名词,包括百度、搜狗、谷歌等。然而,我们建立网站的目的是为了使用户在使用搜索引擎时,通过关键词能够精准地找到我们的网站并使其排名靠前。
搜索引擎的技术架构十分复杂,像百度这样的大企业花费多年时间构建的系统更是难以用几句话概括清楚。在这里,我们将重点介绍搜索引擎的通用架构,如下图所示:
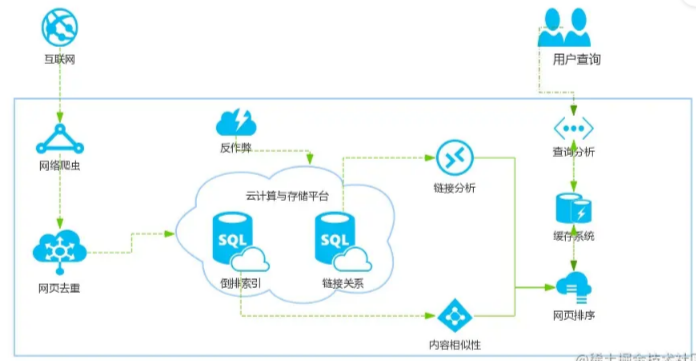
架构图一览,整个系统大致可分为三个关键部分:
面向互联网的爬虫系统 --- 左侧
面向数据的存储系统 --- 中间
面向用户的搜索系统 --- 右侧
其他细节处理则包括这三个系统的相互链接,具体处理细节请参考图表,不再赘述。总体而言,搜索引擎的架构可以简单总结为一句话:搜索引擎通过爬虫系统从互联网上抓取网站信息,将这些信息备份到数据库,用户在搜索时通过关键词直接从数据库中提取数据。
值得一提的是,搜索系统和爬虫系统并非简单的并行或者先后关系。实际上,爬虫系统理论上是持续运行的,不断地抓取与用户相关的关键词,以满足用户的搜索需求。关于当用户搜索一个数据库中没有的关键词时,是否会启动并行的爬取任务以获取相关信息,理论上存在这种可能,但具体情况需根据实际分析而定,这超出了我们讨论的范围。这里提出这个问题只是为了给读者提供一个思考的角度。
注意:由于我们的主题是SEO,而SEO主要针对网络爬虫的爬取,因此我们将重点介绍左侧的爬虫系统。为了更全面地理解搜索引擎的运作,我们将深入探讨爬虫系统的工作原理及其在SEO优化中的关键作用。
二、网络爬虫解析:搜索引擎中的基础组成
网络爬虫,简而言之,是搜索引擎利用的一种内容采集工具,其任务是访问网站并将其内容纳入搜索引擎的索引库中。既然提到了爬虫,那么爬虫到底是什么呢?
网络爬虫是搜索引擎中最基础的组成部分,下面是一个典型网络爬虫的基本架构:
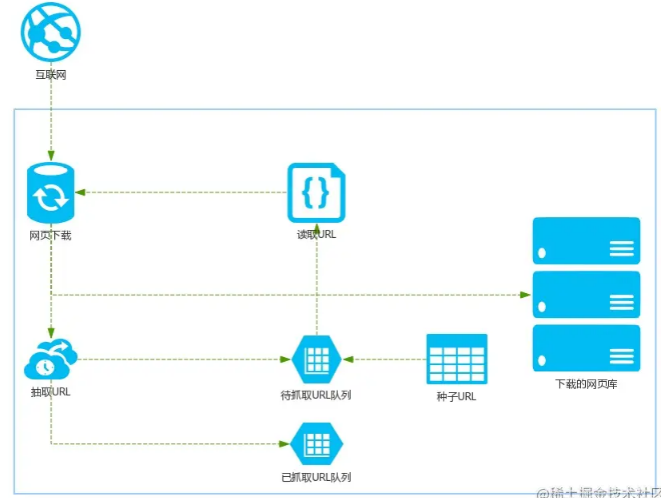
让我们分析一下这张架构图,主要分为以下几个部分:
网页 =(下载)=> 网页库(数据库)
网页 = (读取内部链接)=> 抽取URL =(分析为已抓取)=> 已抓取URL队列
网页 = (读取内部链接)=> 抽取URL =(分析为未抓取)=> 待抓取URL队列 => 读取URL => 循环执行
特别要介绍的是种子URL:种子URL是人为设定的一些URL,供爬虫使用。这可以理解为抓取的入口URL,通过其内部链接再扩散抓取。在查询一些特定信息时,比如非法网站,可以利用这种方式将其周边的不合理网站一并查封,这是个人的一种理解。
理解了搜索引擎和爬虫的基本原理后,我们进行详细的过程分析:
在搜索引擎网站的后台,存在一个庞大的索引库,其中存储了海量的关键词,每个关键词对应许多网址。这些网址是由称为“搜索引擎蜘蛛”或“网络爬虫”的程序从互联网上逐一下载收集而来的。这些勤劳的“蜘蛛”每天在互联网上爬行,从一个链接到另一个链接,下载其中的内容,进行分析和提炼,找到其中的关键词。如果“蜘蛛”认为关键词在数据库中没有而对用户有用,便存入后台的数据库中。反之,如果“蜘蛛”认为是垃圾信息或重复信息,就舍弃不要,继续爬行,寻找最新的、有用的信息保存起来供用户搜索。
当用户进行搜索时,系统从索引库检索与关键字相关的网址,并显示给访客。一个关键词可能对应多个网址,因此排名的问题就变得至关重要。与关键词最匹配的网址通常排在前面。在“蜘蛛”抓取网页内容、提炼关键词的过程中存在一个问题:“蜘蛛”是否能够理解。如果网站内容是Flash和JS等,那么“蜘蛛”无法理解,即使关键字再贴切也无效。相应地,如果搜索引擎能够识别网站内容,就会提高该网站的权重,增加对该网站的友好度,从而提升网站的排名。
三、SEO解析:搜索引擎优化
SEO,即搜索引擎优化,主要任务是通过深入了解搜索引擎抓取互联网页面的方式、索引机制以及关键词排名等技术,对网页进行综合优化。这种优化旨在提高搜索引擎排名,从而增加网站的访问量,最终实现提升网站的销售和宣传能力。通过提高曝光率、增加整站权重,SEO使得用户更容易通过搜索引擎找到特定网站,带来实际的流量。
这一引流策略的优点包括:
1. 低成本: 相比其他推广手段,SEO的成本相对较低。
2. 持久性: 一旦网站优化生效,其影响是持久的,不仅限于某一时期。
3. 免受"无效点击"风险: 避免了通过付费点击广告形式的无效点击风险。在一些搜索引擎,如百度,网站排名不仅依赖于爬虫抓取的结果,还受到人为因素的影响,例如广告费支付和用户点击量计费。若用户误点击频繁,可能导致经济损失。
4. 优化方向
4.1 网站设计优化:
主标题关键词优化:选择精准关键词,通常采用“一个核心词+三五个长尾词”组合成标题。
网站布局优化:企业产品网站以F型布局为主,而内容较多的网站则以“扁平结构”布局为主。
代码优化:对板块和栏目的代码进行优化,最好使用对应的简拼或全拼。
4.2 网站内容优化:
分析栏目关键词,挖掘长尾词,并制成表格形式。
逐个分析长尾词,形成二级长尾词。
根据挖掘的长尾词,分析用户需求,整理相关内容,确保高质量文章发布在网站上。
5. SPA-Single Page Application
SPA,全称为单页面应用,是目前流行的前端框架之一,具有局部刷新、前后端分离、性能优越和成本节约等优点。然而,SPA也存在与SEO相关的缺点。
SPA不利于SEO的原因包括:
爬取页面信息不全: 数据驱动视图,包含大量JavaScript代码,难以被爬取,导致TDK信息不完整。
爬取页面数量有限: 单页面只有一个index.html文件,无法爬取路由子页面,限制了搜索引擎对网站的全面抓取。
综上所述,SPA页面的信息不完整性是影响其排名和流量等一系列问题的主要原因。在考虑使用SPA框架时,需权衡其优势和不利于SEO的特性。
四、Vue中的SPA SEO解决方案:预渲染与服务端渲染
在理解SPA(Single Page Application)的渲染过程之前,我们首先需要了解渲染的基本概念。渲染包括页面的计算过程,涉及到HTML、CSS、和JavaScript的处理。这个计算过程还涉及到数据的处理,DOM Tree、CSSOM Tree以及Render Tree的生成。
渲染可以分为客户端渲染和服务端渲染两种方式:
客户端渲染:
随着Ajax技术的普及和前端框架的兴起(如jq、Angular、React、Vue),前端开始使用JavaScript来渲染页面的大部分内容,以达到局部刷新的效果。在客户端渲染中,HTML仅作为静态文件,服务端在请求时直接返回原始文件给客户端,然后客户端根据HTML上的JavaScript生成DOM并插入HTML中。
服务端渲染:
在服务端渲染中,服务端在返回HTML之前,在特定的区域使用数据填充,然后将生成的HTML返回给客户端。客户端只需要解析HTML,无需再进行DOM的生成。这种方式有助于提高首屏渲染速度,因为不需要等待所有JavaScript下载和执行完成才显示服务端渲染的内容。
在SPA中,为了解决SEO问题,常用的两种解决方案是预渲染和服务端渲染:
方案一:预渲染(Prerender)
预渲染是基于prerender-spa-plugin,在项目构建时通过无头浏览器模拟浏览器请求,将得到的数据插入模板中,生成包含完整静态资源的HTML。这样,网络爬虫可以抓取更多的网站信息。预渲染使用prerender-spa-plugin模块结合webpack生成一些路由对应的静态页面。流程包括访问网站首页,模拟请求配置好的页面,预先加载并生成多个完整页面,供爬虫爬取。
方案二:Vue SSR(服务端渲染)
服务端渲染通过向后端服务器请求数据,生成完整首屏HTML并返回给浏览器。返回给客户端的是已获取了异步数据并执行JavaScript脚本的最终HTML,网络爬虫可以抓取到完整的页面信息。SSR的另一个重要作用是加速首屏渲染,因为无需等待所有JavaScript都完成下载并执行,用户可以更快地看到完整渲染的页面。流程包括访问网站首页,服务端加载所有数据,生成完整的首屏,返回给客户端,然后爬虫可以抓取完整页面。
通过选择合适的渲染方式,SPA可以兼顾良好的用户体验和搜索引擎友好性。