在网络世界中,要保护你的网页免受搜索引擎蜘蛛的检索,你可以运用特定的<meta>标签来告知它们不要访问特定的网页内容。
如果你想了解如何全面阻止搜索引擎蜘蛛检索你的整个网站,可以参考之前的文章(如何使用robots.txt阻止搜索引擎爬取你的网站?)。
同样,你也可以使用相同的标签指示搜索引擎蜘蛛不要扫描页面内容以及追踪页面链接。
这个标签非常实用,甚至当你只想限制网站中的某一页时也能派上用场。
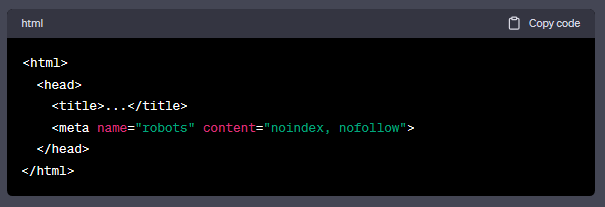
在HTML代码中,“no follow, no index”是基本的设置:
当使用这个标签时,有三个关键点需要记住:
有些网络蜘蛛可能会选择忽略这个标签。通常这些是一些恶意的网络蜘蛛,它们会寻找网络安全漏洞并加以利用,或者是用于电子邮件收集,以便垃圾邮件发送者获取邮箱地址。
NOFOLLOW 指令仅适用于页面上的链接。如果搜索引擎蜘蛛发现了其他页面的链接,而且这些链接没有使用NOFOLLOW,蜘蛛会直接访问该页面。
这里的NOFOLLOW标签不同于在<a href>标签里设置的rel="nofollow"属性。
要撰写专供搜索引擎蜘蛛阅读的标签,可以像其他HTML标签一样放置在HTML代码的头部,就如下面的示例:

让我们继续以上面的例子为基础进行进一步的探讨:
NAME属性为 "ROBOTS"。
CONTENT属性有四种不同的参数可以设置,逗号分隔的参数是允许的,但只有某些组合才是有意义的。如果没有使用这个标签,对搜索引擎蜘蛛来说,默认情况下是使用"INDEX, FOLLOW"的,因此你无需指定也可以被检索到:
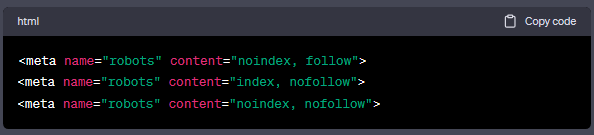
这样设置后,你的网页将按照你的要求被搜索引擎蜘蛛检索。