В магазине сейфов предлагают заказать се...
基本HTML範例 Comment<!DOCTYPE html><html><head> <meta charset="utf-8"/> <title></t...
还有 30 人发表了评论 加入965人围观基本HTML範例 Comment<!DOCTYPE html><html><head> <meta charset="utf-8"/> <title></t...
还有 30 人发表了评论 加入965人围观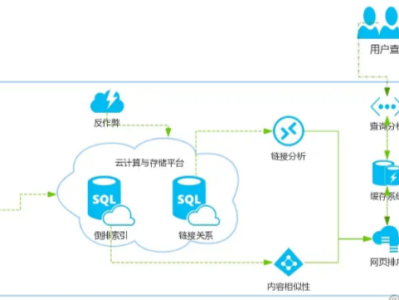
 元智汇电子 发表于2023-12-26 浏览167 评论0
元智汇电子 发表于2023-12-26 浏览167 评论0一、探索搜索引擎的技术奥秘
若想深入了解SEO的解决方案及其背后的原理,我们不可避免地需要探究搜索引擎的本质。对于那些对浏览器工作机制不太熟悉的人来说,搜索引擎可能仅仅是个抽象的名词,包括百度、搜狗、谷歌等。然而,我们建立网站的目的是为了使用户在使用搜索引擎时,通过关键词能够精准地找到我们的网站并使其排名靠前。
 元智汇电子 发表于2023-12-25 浏览174 评论0
元智汇电子 发表于2023-12-25 浏览174 评论0导言
最近,我对项目进行了一轮SEO优化,并在此分享总结。我们都知道,使用Vue/React等框架开发的SPA(单页面应用)天生对SEO不友好。尽管现在有各种技术手段可以改善这一问题,例如使用预渲染,但它们仍然存在一些缺陷。即便如此,Vue/React等框架的潮流仍然难以抵挡。对于一些产品,他们可能凭借其他独特的亮点而不依赖SEO普及,而对于一些需要登录才能使用的应用,SEO也可能显得不那么重要。
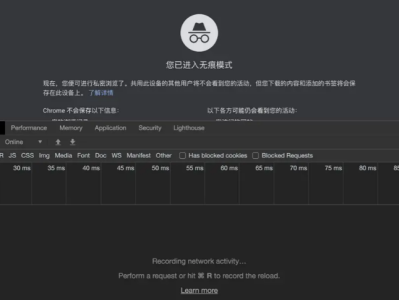 元智汇电子 发表于2023-12-25 浏览173 评论0
元智汇电子 发表于2023-12-25 浏览173 评论0在SEO领域,深入了解如何使用Chrome查看和模拟网络请求中的UserAgent是至关重要的基础知识。通过这项技能,你可以轻松地观察特定URL在不同UserAgent下的响应情况,涵盖了多种场景:
不同设备 - 包括PC和移动设备。
 元智汇电子 发表于2023-12-24 浏览176 评论0
元智汇电子 发表于2023-12-24 浏览176 评论0原理
我们通过在Nginx中拦截并判断User-Agent(ua)是否为爬虫,来实现搜索引擎对于VUE应用的优化。如果不是爬虫,则直接返回页面;如果是爬虫,则先通过PhantomJS进行完整的HTML渲染,然后再返回给搜索引擎。
 元智汇电子 发表于2023-12-24 浏览181 评论0
元智汇电子 发表于2023-12-24 浏览181 评论0在前端开发领域,SEO问题是一个常见挑战,即搜索引擎难以正确爬取和收录网站,从而导致网站在搜索结果中排名较低。为了应对这个问题,我们可以运用Puppeteer来实现服务端渲染(SSR),将网站的HTML代码提供给搜索引擎爬虫。
Puppeteer是由Google Chrome团队开发的Node.js库,提供了一套高级API,用于控制Chrome或Chromium浏览器的各种操作,实现类似人类对浏览器的操作,如打开网页、输入文字、点击按钮等。通过Puppeteer,我们能够轻松进行自动化测试、爬虫、网页截图等任务。
 元智汇电子 发表于2023-12-24 浏览186 评论0
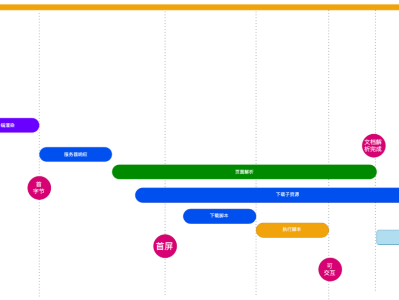
元智汇电子 发表于2023-12-24 浏览186 评论0目前我们采用 Nuxt SSR 完成服务端渲染,以满足 SEO 需求,但将非首屏内容也进行了请求和服务端直出,导致首屏时间延长。为解决这一问题,我们设计并实践了一种自适应 SSR 策略,旨在同时满足 SEO 和用户体验需求。本文将分享该方案的技术细节、设计思路,以及在实施过程中遇到的相关子问题及解决经验。
 元智汇电子 发表于2023-12-23 浏览184 评论0
元智汇电子 发表于2023-12-23 浏览184 评论0项目目标
我们的目标是打造一个综合性网站,涵盖BBS、博客、工具和常用工具类,实现自主运营。在技术选择上,我们要考虑以下关键点。
技术考量要点
 元智汇电子 发表于2023-12-23 浏览183 评论0
元智汇电子 发表于2023-12-23 浏览183 评论0在Next.js的官方文档中,我们可以找到一些关于metadata和sitemap配置的介绍,但总体来说,这只是一个入门指南,未涵盖Next.js开发者通常采用的主流方法。本文旨在深入探讨metadata的配置与管理、sitemap的导出以及网站访问追踪的引入实现,为你提供进一步优化SEO的实用方法。
Metadata配置与管理
 元智汇电子 发表于2023-12-23 浏览180 评论0
元智汇电子 发表于2023-12-23 浏览180 评论0了解搜索引擎的最新能力
随着搜索引擎的不断发展,了解其最新能力变得至关重要。其中,分设备的索引库是一个关键因素。谷歌和百度分别为PC和移动设备建立了不同的索引库,导致相同关键词在不同设备上可能产生不同的搜索结果。
 元智汇电子 发表于2023-12-22 浏览280 评论0
元智汇电子 发表于2023-12-22 浏览280 评论0